created at 2024-09-06
kotlin init 블록 실행 순서
data class Response(
val ci: String?,
) {
init {
ci = ci?:"hashed"
}
constructor(name: String, age: Int) : this(name) {
println("Secondary constructor: Age is $age")
}
}
- 객체 생성 및 필드 주입
- init 블록 실행
- 필드 값이 모두 주입된 후에, init 블록이 실행
- init 블록은 생성자 호출이 끝난 직후 실행되며, 이 시점에서 이미 모든 파라미터가 설정되어 있는 상태
kotlin sequence
일반
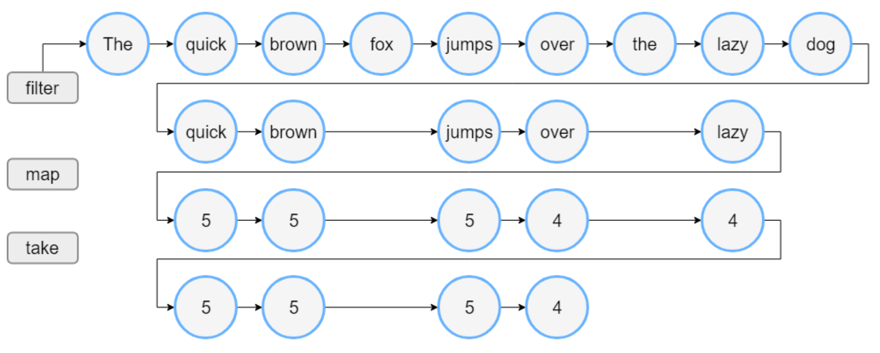
시퀀스
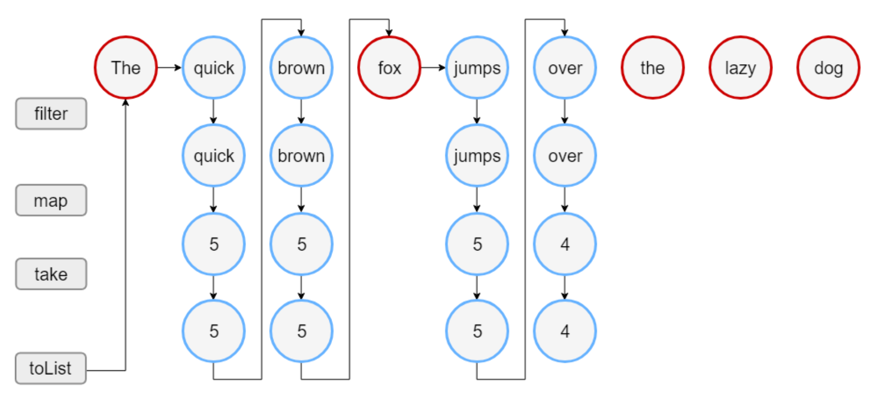
import kotlin.system.measureTimeMillis
class User(val name: String, val age: Int)
fun createRandomUser(): User {
return User("User${(Math.random() * 100).toInt()}", (Math.random() * 100).toInt())
}
fun checkHeap(label: String, previousUsedMemory: Long): Long {
val runtime = Runtime.getRuntime()
val usedMemory = runtime.totalMemory() - runtime.freeMemory()
val memoryIncrease = usedMemory - previousUsedMemory
println("$label - Used Memory: $usedMemory bytes (Increased: ${memoryIncrease} bytes)")
return usedMemory
}
fun t1(users: List<User>): List<String> {
println("Starting t1...")
val initialMemory = getHeapMemory()
var previousUsedMemory = initialMemory
val result = measureTimeMillis {
val filtered = users.filter { it.age % 2 == 0 } // 중간 컬렉션 생성
previousUsedMemory = checkHeap("After filter in t1", previousUsedMemory)
val mapped = filtered.map { it.name } // 또 다른 중간 컬렉션 생성
previousUsedMemory = checkHeap("After map in t1", previousUsedMemory)
println("Total Memory Increase in t1: ${previousUsedMemory - initialMemory} bytes")
return mapped
}
println("t1 Execution Time: $result ms")
}
fun getHeapMemory(): Long{
val runtime = Runtime.getRuntime()
return runtime.totalMemory() - runtime.freeMemory()
}
fun t2(users: List<User>): List<String> {
println("\nStarting t2...")
val initialMemory = getHeapMemory()
var previousUsedMemory = initialMemory
val result = measureTimeMillis {
val sequence = users.asSequence().filter { it.age % 2 == 0 } // 지연 평가, 중간 컬렉션 없음
previousUsedMemory = checkHeap("After filter in t2", previousUsedMemory)
val mapped = sequence.map { it.name } // 여전히 중간 컬렉션 없음
previousUsedMemory = checkHeap("After map in t2", previousUsedMemory)
val resultList = mapped.toList() // 이 때 모든 연산 수행
previousUsedMemory = checkHeap("After toList in t2", previousUsedMemory)
println("Total Memory Increase in t2: ${previousUsedMemory - initialMemory} bytes")
return resultList
}
println("t2 Execution Time: $result ms")
}
fun main() {
// 큰 리스트 생성
val users = List(1_000_000) { createRandomUser() }
t1(users)
t2(users)
}
Starting t1...
After filter in t1 - Used Memory: 91721368 bytes (Increased: 6229824 bytes)
After map in t1 - Used Memory: 94891576 bytes (Increased: 3170208 bytes)
Total Memory Increase in t1: 9400032 bytes
Starting t2...
After filter in t2 - Used Memory: 94891576 bytes (Increased: 0 bytes)
After map in t2 - Used Memory: 94891576 bytes (Increased: 0 bytes)
After toList in t2 - Used Memory: 101846240 bytes (Increased: 6954664 bytes)
Total Memory Increase in t2: 6954664 bytes
실제로 실험 결과 중간 결과값을 저장. sequence 는 lazy 하며 한호흡으로 처리하기때문에 중간 컬렉션 생성하지 않는다. (intellij 에서 profiler 로 쉽게 확인가능!)
즉, 컬렉션 크기가 크며 filtering 이후 후처리 더 필요하다면 sequence 로 처리하는게 좋을듯. 특히 .take(...) 쓰게 된다면 stream 으로 처리하는 sequence 가 당연 빠르다.
만약 후치러 하지 않거나 컬렉션 크기가 작다면 일반 컬렉션을 사용하는게 더 좋을듯. 추가 lazy 를 위한 바이트가 더 들어가기때문에 오히려 메모리를 더 먹을 수가 있음.
OffsetDateTime 사용 시 equals or isBefore 에 대한 두 가지 방법
if (date1.before(date2) || date1.equals(date2)) {
// 바로 이해하기 쉬움
}
if (!date1.isAfter(date2)) {
// 짧지만 바로 이해하기 어려워서 안쓸듯?
}