서론
저희 팀은 유저 주문 시 발생하는 알림 전송 로직을 기존에는 주문 처리 흐름 안에 직접 포함해 운영하고 있었습니다. 이 알림 로직은 PUSH → SMS → 알림톡 순서로 failover 되며, 각 단계가 순차적으로 처리되는 구조입니다. 문제는 이 모든 과정이 동기적이고 블로킹된다는 것이죠. 예를 들어 외부 서비스의 타임아웃이 각 단계마다 5초라면, 최악의 경우 주문 요청이 최대 15초간 지연될 수 있습니다. 즉, 유저가 주문을 눌렀을 때, 실제 주문 완료까지 15초를 기다려야 하는 상황이 발생합니다.
그래서 저희는 알림 전송과 같은 시간이 오래 걸리는 작업을 메인 로직에서 분리하여 비동기적으로 처리하기로 결정했고, 이를 위해 메시지 큐를 도입하기로 했습니다.
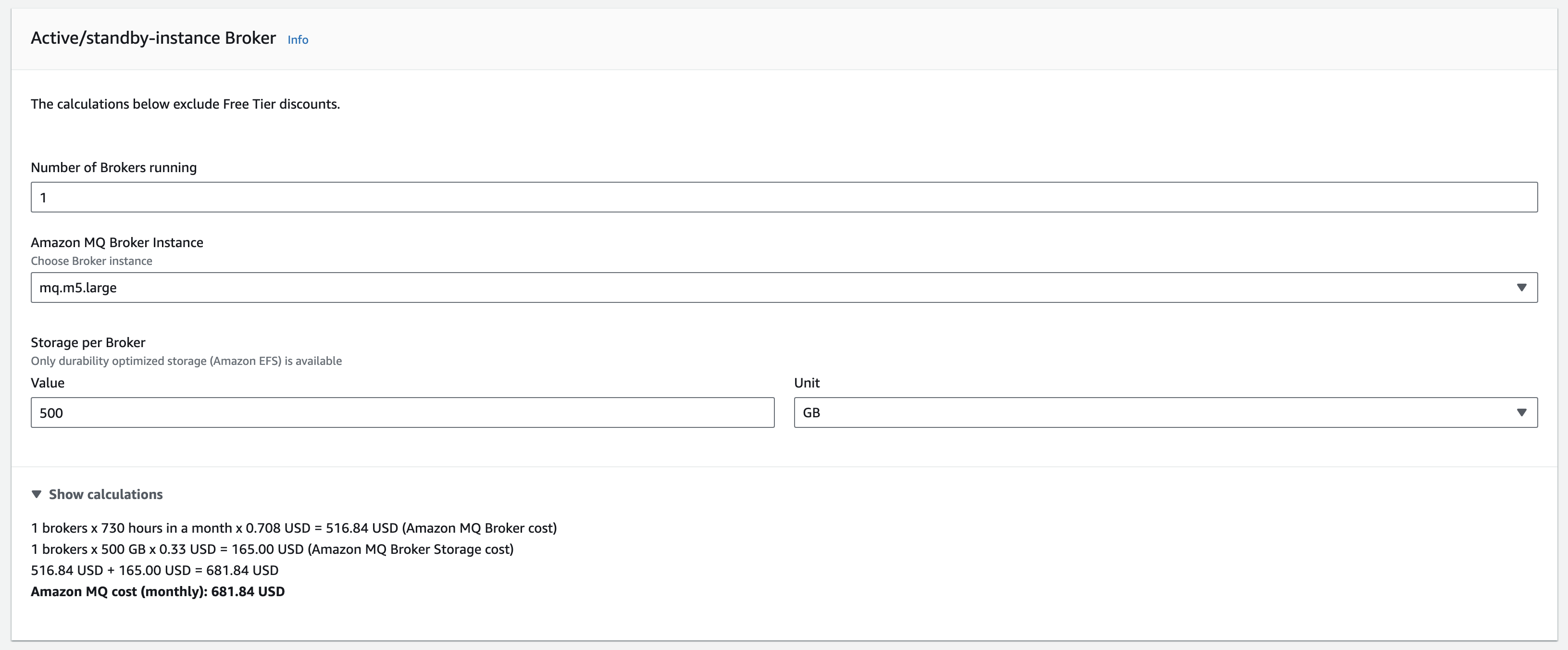
처음에는 Amazon Kafka를 고려했습니다. AWS Client VPN 연동이나 IAM 기반 인증 등 운영 측면에서 편리합니다. 하지만 비용을 확인해보니, 싱글 브로커 기준으로 월 약 100만원 수준이었습니다. 또한, 이번에 분리하려는 노티 시스템 +a는 디스크 기반의 영구 저장이 필요하지 않고 당장 수평 확장까지 고려할 상황도 아니었기에 과한 선택이라는 판단이 들었습니다. 개발 리소스도 더 필요하구요.
또한 우리가 만들려는 비동기 알림 전송 시스템은 다음과 같은 특성을 가지고 있었습니다.
- 메세지 “처리 순서” 보장 불필요 - 단일 파티션을 여러 컨슈머가 병렬로 처리하기때문에 순서 보장 불가능
- 메세지의 영구 저장이 필요하지 않음 - 메세지 전송하면 딱히 이벤트를 다시 꺼내볼 일 없음
- 빠른 처리 속도 우선 - 알림 전송 지연 최소화
- 낮은 인프라 비용 우선 - 비용이 많이 드는 솔루션은 놉
그래서 redis stream 이 이 모든 조건에 부합하였고 아래는 설계 포인트입니다.
- 이벤트 실패처리
- 이벤트 균등분배
- DLQ(Dead Letter Queue)
- consumer 관리
하나씩 볼까요?
요약 먼저! 기술적 문제와 해결 방법
먼저 abstract 부터 보시죠. “그래서 어떤 문제가 있었고 어떻게 해결했는데?” 를 시간순서대로 요약 및 표로 나타내었습니다.
| 문제 순서 | 문제 발견 | 방향 설정 | 수정 방법 | 해결된 문제 |
|---|---|---|---|---|
| 1 | 알림 로직이 동기 블로킹되어 주문 응답 지연 (최대 15초) | 알림을 메인 로직에서 분리하여 비동기 처리 | Amazon Kafka 나 Redis Stream 기반 MQ 도입 | 주문 속도 개선 |
| 2 | Amazon MQ는 비용 과다 및 과한 기능 | Redis Stream으로 대체 | 기존 Redis 의 Stream 기능으로 MQ 직접 구축 | 비용 절감, 간단한 수준의 운영 가능 |
| 3 | 죽은 consumer가 PEL 메시지 방치 | timeout 메시지를 다른 consumer가 회수 | XAUTOCLAIM, XCLAIM, 주기적 PEL 조회 | 장애 복구 가능, 메시지 유실 방지 |
| 4 | 실패 이벤트들이 특정 consumer에만 분배 | 실패 이벤트 균등 분배 | min(hash(eventId + consumerId)) 기반 할당, 락 처리 | 실패 이벤트 균등 분배 |
| 5 | consumer 추가 시 중복 처리 발생 가능 | 처리 전 mutex 설정해서 선점 | Redis Lock으로 이벤트 단독 소비 보장 | 중복 소비 방지, 데이터 정합성 유지 |
| 6 | 실패 메시지 무한 재시도 | 실패 횟수 기준 DLQ 분기 | 횟수 초과 시 DLQ로 이동, 로깅 | 시스템 안정성 향상, abnormal한 이벤트 격리 |
| 7 | consumer 상태 추적 불가 | consumer 생존 여부 직접 관리 | key + TTL, Set 기반 Heartbeat 구현 | 실시간 consumer 관리, 기준(consumerId) 확보 |
| 8 | Stream이 메모리 기반이라 용량 관리에 민감 | 오래된 메시지 삭제 처리 | XDEL로 과거 이벤트 순차 제거 | 메모리 누수 방지 |
이벤트 재처리
Redis Stream에서 consumer가 XREADGROUP 명령을 통해 이벤트를 소비하면, 해당 이벤트는 PEL(Pending Entry List) 에 등록됩니다. 이 상태는 “메시지를 가져갔지만 아직 처리 완료(ACK)하지 않았다”는 의미입니다. 만약 consumer가 메시지를 처리하는 도중에 1) 죽거나 2) 예외가 발생해 ACK를 보내지 않으면, 해당 메시지는 계속 PEL에 남아 있게 됩니다. 이 때 일정 시간(idle_time)이 지난 후에도 ACK되지 않은 메시지는, 다른 살아있는 consumer가 XAUTOCLAIM 또는 XCLAIM 명령을 통해 가져가서 재소비 해야합니다. 이렇게 메시지를 다른 곳에서 이전하여 처리는 과정을 “이벤트 재처리” 이라고 부릅니다. 그러면 정의 이후 구현은 간단하죠!
consumer 들이 주기적으로 PEL 를 조회하여 처리실패 된 이벤트를 가져와서 재처리하도록 구현하면됩니다.
추가로 메모리 기반 한정된 용량이므로 xdel 로 일정이상 큐에 쌓이면 옛날 이벤트 순으로 제거해야합니다.
실패 이벤트 균등분배
저는 consumer들이 1초 주기 스케줄러로 XPENDING 로 리스트(ACK 가 오지않은 이벤트들)를 반환하여 소비시점으로부터 오랜 시간이 지난 이벤트들을 실패 이벤트로 규정 및 처리하도록 구현하였습니다. 하지만 이 방법에는 문제가 있습니다. consumer-1,2,3 이 있을 때 한번 스케줄러가 시작되면 변수없이 linear 하게 순서가 정해진다는 것입니다. consumer-1 가 먼저 실행되면 항상 consumer-1 은 첫 번째로 실행된다는 거죠. 대부분의 경우 문제없지만 아래의 경우 문제가 발생합니다.
- consumer-1: 항상 1초 타이밍에 정확히 요청
- consumer-2: 1.1초에 요청
- consumer-3: 1.2초에 요청
어떤 문제가 있는지 보기 편하게 좀 더 편하게 도식화해볼게요.
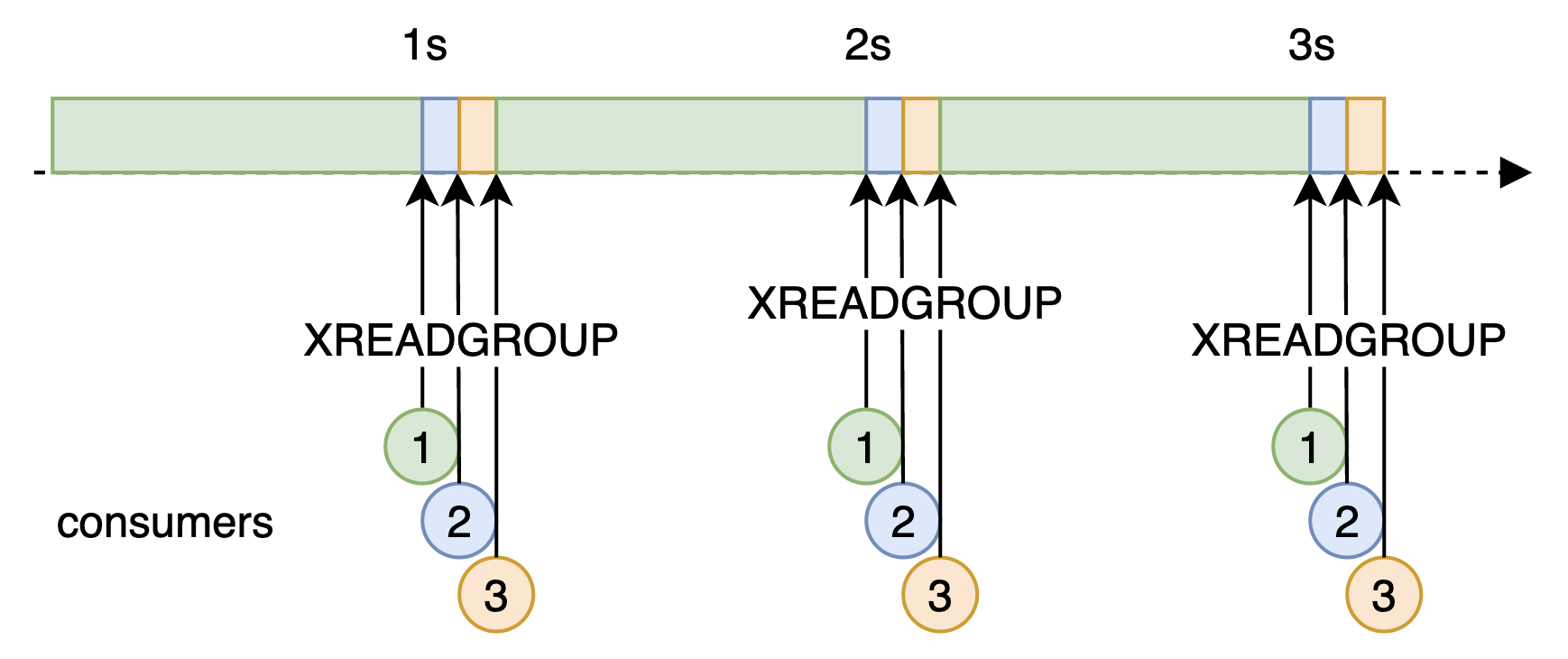
초록색 consumer의 지분이 매우 많은게 눈에 보이죠? 이벤트가 일정하게 수신된다는 가정하에 consumer-1은 80% 실패 이벤트를 맡아서 처리하고 나머지는 각각 10%씩 맡습니다. 그리고 이는 consumer 간 최초 시작 시간이 가까울 수록 더 크게 불균형해집니다. 운이 나쁘면 consumer-1 이 99.99…% 의 실패 이벤트를 처리할 수 있다는 것이죠.
이 문제를 두 가지 방법으로 풀 수 있습니다.
- consumer 별 (1 ~ 1.x초) 랜덤한 시간을 주기로 가지도록.
- 간편하게 처리할 수 있습니다.
- 완전균등분배는 어렵습니다.
- min(hash(event-id + consumer-id)) 인 consumer 가 해당 이벤트 처리
- XINFO GROUPS 를 통해 특정 Consumer Group의 last-delivered-id를 얻고, 해당 ID 이후의 메시지 ID 목록을 쿼리.
- consumer 들은 현재 살아있는 consumer-id 리스트를 받아와서 “그래서 이 이벤트는 누가 처리할건데?”를 위의 식으로 알 수 있어야합니다.
- 이벤트 중복 consume 을 막아야합니다.
- 모든 이벤트가 균등하게 분산됩니다.
간단하게 2의 순서를 나타내면 아래와 같습니다.
- 이벤트 재처리: XPENDING →
aliveConsumerIds.minByOrNull { hash(eventId + it) } == myConsumerId→ XREADGROUP → XACK
재처리가 아닌 일반 소비는 아래처럼 설정하면 XREADGROUP → 수신 → XREADGROUP → … 반복하여 균일한 이벤트 소비가 가능합니다.
private fun initListener() {
val listenerContainer = StreamMessageListenerContainer.create(
redisTemplate.connectionFactory,
StreamMessageListenerContainer.StreamMessageListenerContainerOptions.builder()
.targetType(String::class.java)
.pollTimeout(Duration.ofMillis(streamConfig.pollTimeoutMs))
.build(),
)
listenerContainer.receive(
Consumer.from(streamConfig.consumerGroupName, PodContext.id),
StreamOffset.create(streamConfig.streamKey, ReadOffset.lastConsumed()),
listener,
)
listenerContainer.start()
}
그리고 이벤트 재처리 시 중복처리방지가 있어야합니다. 새로운 consumer 가 등장할 경우 이벤트를 중복해서 처리할 수 있기 때문입니다.
예시를 들어볼까요? consumer-1이 XPENDING 으로 실패한 이벤트들을 가져옵니다. 그리고 aliveConsumerIds.minByOrNull { hash(eventId + it) } == myConsumerId 조건을 만족해 event-a를 처리하게 됐습니다. 그런데 이벤트를 처리하는 도중, consumer-2가 새로 등록되면서 aliveConsumerIds에 추가되고 동일한 로직을 수행하면, 같은 event-a에 대해 본인이 처리담당이라고 판단하게 될 수 있습니다.
즉, 새로운 consumer가 추가될 경우 중복처리될 가능성이 있기때문에 consumer-1 은 이벤트를 실제로 소비하기이전 lock 을 걸고 소비해서 중복소비를 제한해야합니다.
DLQ
PEL 에서는 이벤트가 몇 번 소비되었는지 함께 저장하고 있습니다. 만약 소비 횟수가 threshold 를 넘어가도 계속해서 놔두면 무한대로 소비되기떄문에 비정상 이벤트를 따로 빼서 처리를 해줘야겠죠! 이를 일단 ack 날리고 DLQ 에 따로 빼서 수동보정을 하든, 로깅을 따로 영구적으로 하든 처리를 해야합니다.
consumer 관리
Redis Stream 은 Kafka 처럼 consumer 상태 추적기능을 제공하지 않습니다. 그리고 저는 consumer들에게 이벤트 균등분배를 위해 동기화된 consumer 리스트가 필요하죠. 두 가지 방식으로 동기화시킬 수 있습니다.
XINFO CONSUMERS로 consumer 리스트 관리- 직접 리스트 관리 & 동기화
Redis stream 에는 XINFO CONSUMERS 명령어로 그룹 내 consumer 들을 확인할 수 있습니다. 하지만 해당 기능으로 consumer 관리하기 별로 좋지 않습니다. 이유가 무엇일까요?
XINFO CONSUMERS 로 consumer 을 가져와서 죽은 consumer 을 처리할 때 판단방식은 idle_time 이 일정주기 이상인 경우를 죽은 노드라고 판단 후 제거하게됩니다. 문제는 이벤트 자체가 없을 경우에도 idle_time이 증가한다는 것입니다. 그래서 단지 이벤트가 없을 뿐인데 멀쩡한 consumer를 제거해버립니다.
그래서 저는 따로 관리를 하였습니다. consumer 들은 일정 주기로 자신의 id 를 key + ttl 로 등록 및 set 에 추가하도록 말이죠. 그리고 set 에 sadd 합니다. 그래서 set 보고 key 확인 후 ttl 만료되서 사라졌으면 set 에서 제거하고 key 존재하면 살아있는 노드라고 판단하는거죠. set 은 내부 value 에 ttl 설정이 안되서 key 로 ttl 설정을 따로 해주었습니다. key 를 {streamKey}:alive:nodes:* 와일드카드로 검색할 순 있긴 한데 아시다시피 인덱싱 되어있지 않아서 풀스캔을 해버리겠죠? 그래서 set 을 따로 두었습니다. 또한 주기적으로 동기화 시켜주는 스케줄러 만들고 추가로 XINFO 내 consumer 이랑도 동기화시켜 주어야합니다. consumer 가 무한정 쌓이기 때문이죠.
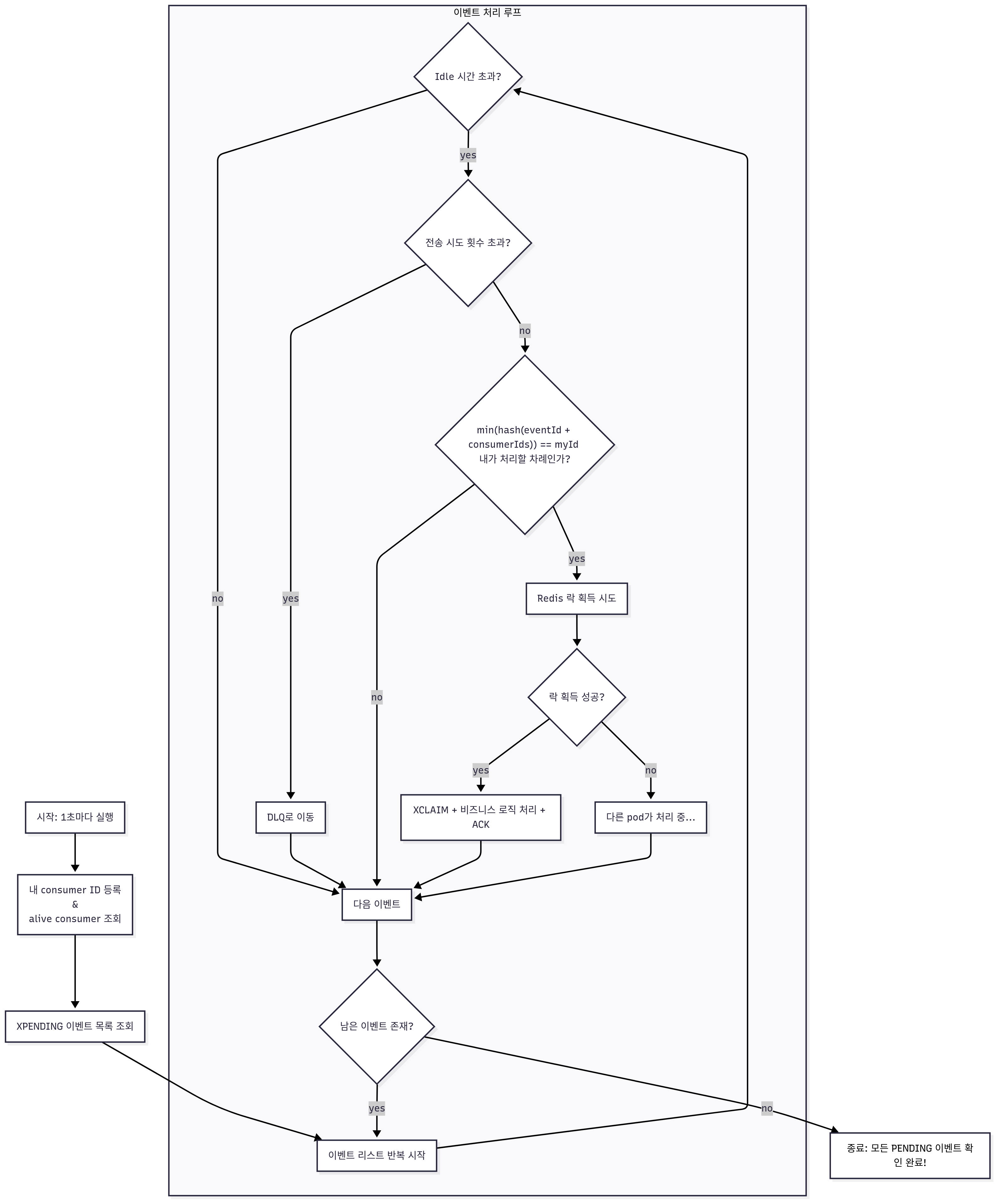
그래서 실패 이벤트 재처리 종합 플로우는 아래와 같습니다(머메이드로 작성해봤는데 되게 편하네요).
응용
이것저것 만져보니 응용도 가능했습니다. 각 Pod에서 자신과 연결된 WebSocket 세션에 대해 일괄적으로 이벤트를 전송하는 기능도 구현할 수 있었습니다.
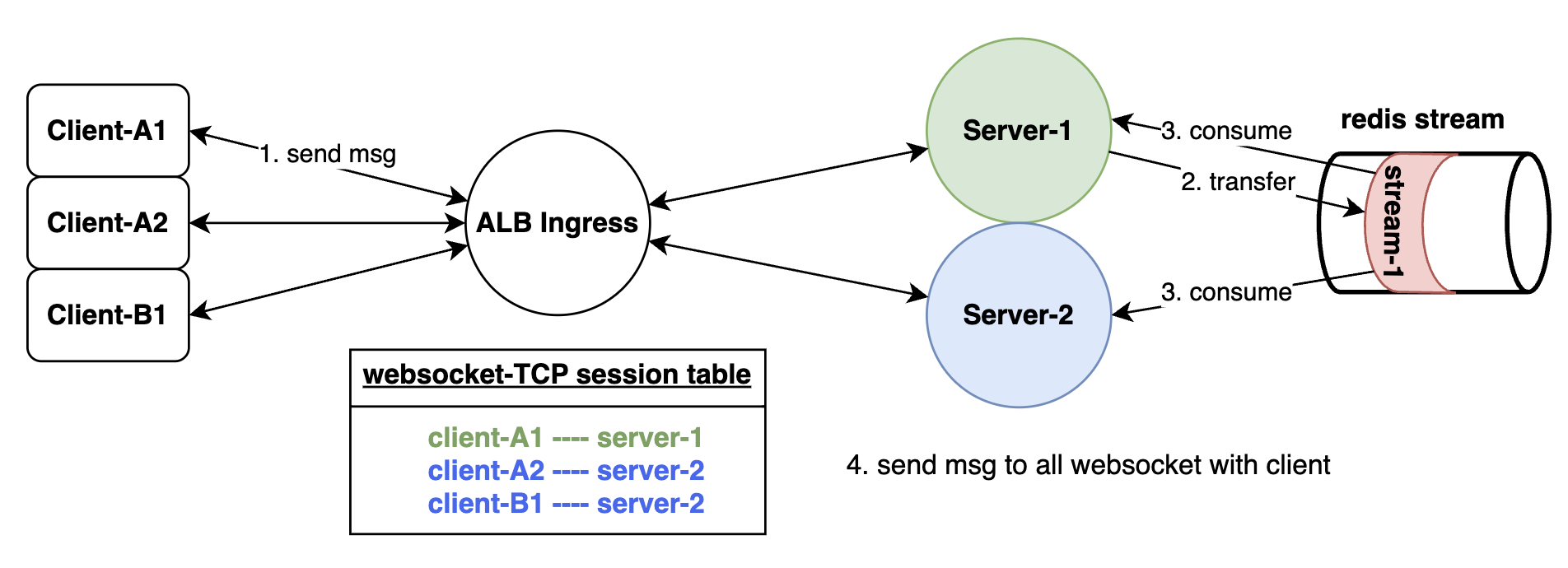
client-A1 이 요청을 전송하면 서버가 처리하여 stream 으로 이벤트를 전송합니다. 이후 해당 stream 을 개별 중복 소비해서 처리하도록 하면! 각각의 서버들은 자신과 연결된 웹소켓에 메세지를 뿌릴 수 있게 됩니다.
저희는 다중 클라이언트에게 웹소켓을 통한 동일 메세지 전송 지원을 위해 위와 같은 방식으로 구현하였습니다.
또한 별도이 스레드풀로 XREADGROUP 을 처리함으로써 메인 스레드풀과 분리하여 안정적으로 이벤트를 처리할 수 있도록 하였습니다.
후기
프레임워크나 외부 도구에 의존하지 않고, raw하게 구조를 설계하고 자동화하며, 문제를 하나씩 뜯어보며 해결하는 과정이 제가 선호하는 방식이었고(너무 낮은 레벨만 아니라면) 덕분에 정말 몰입해서 작업할 수 있었습니다.
물론 Redis는 Kafka처럼 파티션이나 디스크 기반의 안정적인 메시지 보관 기능이 없고, 리밸런싱이나 consumer 추적도 직접 구현해야 했습니다. 휘발성이 강하다는 단점도 있죠. 그렇지만 알림이나 이벤트 전송처럼 비교적 가벼운 메시지 처리에는 Redis Stream이 훨씬 가볍고 빠르게 대응할 수 있습니다. 무엇보다도, 직접 설계하고 구현하는 과정을 통해 시스템이 어떻게 작동해야 하는지에 대해 더 깊이 이해할 수 있었던 좋은 기회였습니다.
정리하자면, 이 프로젝트를 통해 한정된 자원 안에서 “메시징 시스템이 어떻게 작동해야 하는가?” 를 구조적으로 고민해볼 수 있어서 좋은 경험이였습니다.
Introduction
Our team used to operate notification sending logic, triggered when a user placed an order, directly inside the order processing flow. This notification logic failed over in the order PUSH -> SMS -> AlimTalk, and each step was processed sequentially. The problem is that this whole process is synchronous and blocking. For example, if the timeout of the external service is 5 seconds for each step, the order request can be delayed by up to 15 seconds in the worst case. In other words, after the user presses the order button, they may have to wait 15 seconds until the order is actually completed.
So we decided to separate long-running work such as notification sending from the main logic and process it asynchronously. For that, we decided to introduce a message queue.
At first, we considered Amazon Kafka. It is convenient operationally, with AWS Client VPN integration and IAM-based authentication. But after checking the cost, it was around 1 million KRW per month for a single broker. Also, the notification system plus alpha that we wanted to separate did not require disk-based permanent storage, and it was not yet a situation where horizontal scaling had to be considered. So it felt excessive. It would also require more development resources.
The asynchronous notification system we wanted to build had the following characteristics.
- Message “processing order” does not need to be guaranteed, because a single partition is processed in parallel by multiple consumers, so order cannot be guaranteed.
- Permanent message storage is not needed, because once a message is sent, there is usually no need to read the event again.
- Fast processing speed is the priority, to minimize notification delay.
- Low infrastructure cost is the priority, so expensive solutions are not acceptable.
So Redis Stream matched all of these conditions, and the design points were as follows.
- Event failure handling
- Even event distribution
- DLQ, Dead Letter Queue
- Consumer management
Let us look at them one by one.
Summary first: technical problems and solutions
Let us start with the abstract. I summarized “what problems existed and how they were solved” in chronological order and represented them as a table.
| Order | Problem found | Direction | Fix | Solved problem |
|---|---|---|---|---|
| 1 | Notification logic was synchronous/blocking and delayed order responses, up to 15 seconds | Separate notification from main logic and process asynchronously | Introduce MQ based on Amazon Kafka or Redis Stream | Improved order speed |
| 2 | Amazon MQ was too expensive and had excessive features | Replace with Redis Stream | Build MQ directly using the existing Redis Stream feature | Cost reduction, simple operations possible |
| 3 | Dead consumers left PEL messages behind | Let another consumer recover timeout messages | XAUTOCLAIM, XCLAIM, periodic PEL lookup | Failure recovery possible, message loss prevented |
| 4 | Failed events were distributed only to a specific consumer | Distribute failed events evenly | Assignment based on min(hash(eventId + consumerId)), lock handling | Even failed-event distribution |
| 5 | Duplicate processing could happen when a consumer is added | Preempt with mutex before processing | Guarantee exclusive event consumption with Redis Lock | Prevent duplicate consumption, maintain data consistency |
| 6 | Failed messages retried infinitely | Branch to DLQ based on failure count | Move to DLQ and log when count is exceeded | Improve system stability, isolate abnormal events |
| 7 | Consumer state could not be tracked | Manage consumer liveness directly | Heartbeat based on key + TTL and Set | Real-time consumer management, consumerId criteria secured |
| 8 | Stream is memory-based and sensitive to capacity management | Delete old messages | Sequentially remove old events with XDEL | Prevent memory leaks |
Event reprocessing
When a consumer consumes an event with XREADGROUP in Redis Stream, that event is registered in the PEL, Pending Entry List. This state means “the message was taken, but processing has not been completed with ACK yet.” If the consumer dies while processing the message or an exception occurs and ACK is not sent, the message stays in the PEL. If a message is not ACKed even after a certain idle time, another live consumer must take it with XAUTOCLAIM or XCLAIM and consume it again. This process of moving and processing a message elsewhere is called “event reprocessing.” Once defined like this, the implementation is simple.
Consumers periodically query the PEL, take failed events, and reprocess them.
Also, because Redis Stream is memory-based and has limited capacity, old events should be removed with
XDELonce the queue grows beyond a certain level.
Even distribution of failed events
I implemented consumers so that a scheduler runs every second and uses XPENDING to return a list of events that have not received ACK. Events that have been around for a long time since consumption are treated as failed events and processed. But this method has a problem. If there are consumer-1, consumer-2, and consumer-3, once the scheduler starts, the order is determined linearly without variation. If consumer-1 runs first, consumer-1 is always first. In most cases this is fine, but the following case creates a problem.
- consumer-1: requests exactly every 1 second
- consumer-2: requests at 1.1 seconds
- consumer-3: requests at 1.2 seconds
To make the problem easier to see, I drew it more simply.
You can see that the green consumer owns a very large share. Assuming events are received steadily, consumer-1 handles 80% of failed events, and the others handle 10% each. This imbalance gets worse as the initial start times of the consumers get closer. If unlucky, consumer-1 can process 99.99…% of failed events.
There are two ways to solve this.
- Give each consumer a random interval of 1 to 1.x seconds.
- Easy to handle.
- Perfectly even distribution is difficult.
- Let the consumer with
min(hash(event-id + consumer-id))process the event.- Use
XINFO GROUPSto get the last-delivered-id of a specific consumer group, then query the list of message IDs after that ID. - Consumers need to obtain the list of currently alive consumer ids and use the formula above to decide “who should process this event?”
- Duplicate event consumption must be prevented.
- All events are distributed evenly.
- Use
A simple flow for option 2 is below.
- Event reprocessing: XPENDING ->
aliveConsumerIds.minByOrNull { hash(eventId + it) } == myConsumerId-> XREADGROUP -> XACK
For normal consumption, not reprocessing, you can configure it like below and repeat XREADGROUP -> receive -> XREADGROUP, allowing uniform event consumption.
private fun initListener() {
val listenerContainer = StreamMessageListenerContainer.create(
redisTemplate.connectionFactory,
StreamMessageListenerContainer.StreamMessageListenerContainerOptions.builder()
.targetType(String::class.java)
.pollTimeout(Duration.ofMillis(streamConfig.pollTimeoutMs))
.build(),
)
listenerContainer.receive(
Consumer.from(streamConfig.consumerGroupName, PodContext.id),
StreamOffset.create(streamConfig.streamKey, ReadOffset.lastConsumed()),
listener,
)
listenerContainer.start()
}
During event reprocessing, duplicate processing prevention is needed. A new consumer can appear and process the same event again.
For example, consumer-1 gets failed events with XPENDING. It satisfies aliveConsumerIds.minByOrNull { hash(eventId + it) } == myConsumerId, so it starts processing event-a. But while the event is being processed, consumer-2 is newly registered and added to aliveConsumerIds. If it runs the same logic, it may decide that it is responsible for the same event-a.
In other words, when a new consumer is added, duplicate processing can happen. So consumer-1 must acquire a lock before actually consuming the event and limit duplicate consumption.
DLQ
The PEL also stores how many times an event has been consumed. If a message keeps getting retried even after the consumption count exceeds a threshold, it will be consumed forever, so abnormal events should be separated and handled. For now, they should be ACKed and moved separately to a DLQ for manual correction, or logged permanently.
Consumer management
Redis Stream does not provide consumer state tracking like Kafka. But I needed a synchronized consumer list for even event distribution among consumers. There are two ways to synchronize it.
- Manage the consumer list with
XINFO CONSUMERS - Manage and synchronize the list directly
Redis Stream provides the XINFO CONSUMERS command to check consumers inside a group. But this feature is not very good for consumer management. Why?
When XINFO CONSUMERS is used to fetch consumers and determine dead consumers, it treats a consumer as dead if its idle time exceeds a certain period. The problem is that idle time also increases when there are no events. So it can remove a healthy consumer just because there were no events.
So I managed this separately. Consumers periodically register their id as key + ttl and also add it to a set. The system checks the set, then checks the key. If the TTL expires and the key disappears, it removes that id from the set. If the key exists, it treats the node as alive. Since Redis sets cannot set TTL on internal values, TTL is set separately on keys. You can search keys with a wildcard like {streamKey}:alive:nodes:*, but as you know, it is not indexed and will cause a full scan. So I kept a separate set. Also, a scheduler needs to periodically synchronize this and also synchronize it with consumers inside XINFO, because consumers accumulate indefinitely.
The overall failed-event reprocessing flow is below. I wrote it with Mermaid, and it was quite convenient.
Application
After trying a few things, I found that this could also be applied elsewhere. I was able to implement a function where each pod broadcasts events in bulk to the WebSocket sessions connected to itself.
When client-A1 sends a request, the server processes it and sends an event to the stream. Then, if each server consumes that stream separately without duplication, each server can broadcast messages to the WebSockets connected to itself.
We implemented this approach to support sending the same message to multiple clients through WebSocket.
Also, by processing XREADGROUP with a separate thread pool, we separated it from the main thread pool and made event processing more stable.
Retrospective
Designing and automating the structure directly, without relying on a framework or external tool, and solving problems one by one was the way I prefer to work, as long as it is not too low-level. Because of that, I was able to get really immersed in the work.
Of course, Redis does not have Kafka-like partitions or stable disk-based message retention, and rebalancing and consumer tracking need to be implemented directly. It is also more volatile. But for relatively lightweight message processing such as notifications or event delivery, Redis Stream can respond much more lightly and quickly. Most importantly, directly designing and implementing it was a good opportunity to understand more deeply how the system should work.
To summarize, this project was a good experience because it made me think structurally about “how should a messaging system work?” within limited resources.