요즘 gRPC 를 외/내부망 통신에 많이 사용하는 추세이다. 듣기로는 소형 이진포멧으로 페이로드 크기를 줄일 수 있다고 한다. 성능 최적화에 기여할 수 있을 것 같아서 평소에 restAPI 만 쓰다가 이참에 gRPC 에 대해 알아보기로 했다.
protobuf 이진 내부구조 동작방식
gRPC 는 HTTP/2 + Protobuf 를 사용하는 RPC 이다. RPC 는 쉽게 말하면 서버의 특정함수를 원격으로 실행시키는 것임. 그리고 요즘 이 gRPC 가 많이 쓰이는 이유는 페이로드 크기를 줄일 수 있기 때문이다. 간단하게 아래의 json 을 protobuf 로 전송할 때 얼마나 소형으로 전송할 수 있는지 직접 계산해보자.
{
"name": "A",
"age": 30,
}
위 json 을 그대로 전송하면 key 랑 value 전부 바이트 변환했을 때 21 bytes 가 나온다. 이제 protobuf 스키마를 정의해보자.
message Person {
string name = 1;
int32 age = 2;
}
gRPC HEX 덤프보면 아래와 같이 찍힌다.
0A 01 41 | 10 1E
여기서 매우 재밌는 부분이 0A 와 10 부분이다. protobuf 직렬화 포맷을 보면 각 필드는 key-value 쌍으로 저장된다. key 는 타입이랑 필드 번호를 합쳐서 저장하는데 아래와 같이 계산된다.
key = (field_number << 3) | wire_type
wire_type 이 말 그대로 타입이고 matching table: https://developers.google.com/protocol-buffers/docs/encoding#structure 이 있다. 이거보고 타입에 맞춰 비트 연산해주면 된다. string 의 경우 2 (length-delimited), int32 의 경우 0 (varint) 임. 하위 3비트가 2면 길이도 나온다고 보면 된다. 그래서 name 필드는 (1 « 3) + 10(2) = 1010(2) = 0A(16) 으로 저장된다. 이진으로 읽으면 1 번쨰 필드가 010(2 = string)타입을 가지고 있다는 뜻이 된다. 만약에 필드번호가 8이다라고 하면 1000 000 이 되고, wire_type 2 를 합치면 1000 010 이 된다. 이걸 16진수로 바꾸면 42 가 된다.
그럼 필드번호가 매우 크다면 어떻게 될까?? key 가 8bit 로만 해결되지 않을 것 같은데, 이 점이 궁금해서 찾아봤더니 varint 인코딩 방식으로 key 2개로 쪼개져서 저장된다고 한다. 뭐 varint 는 7bit+ continuation_bit 1 로 저장하는 방식임. 그래서 아무리 큰 수라도 여러 byte 로 쪼개져서 저장될 수 있다. 최초 key 가 continuation_bit 1 로 설정된 다음 나오고, 2번째 key 는 continuation_bit 0 으로 세팅 및 3번째부터 실제 value 가 등장한다.
이제 0A 01 41 가 길이 1인 string ‘A’ 라는 것을 알았다. 이제 10 1E 부분을 보자. 10(16) 0001 0000(2) 으로 필드번호는 10(2) = 2, wire_typ = 0 으로 int 형이라는 것을 알 수 있다. 얘는 따로 길이가 없어서 바로 value 가 등장한다. 1E(16) = 30(10) 으로 age 가 30 이라는 것을 알 수 있다!
그래서 최종적으로 gRPC 로 전송되는 페이로드는 0A 01 41 10 1E 로 총 5byte 로도 충분히 그 뜻을 전달이 가능하다. 다만 중간에 사람이 읽기 좀 어렵다는 단점이 있다. 그래서 string ‘A’ 가 어떤 값인데? 를 알기 위해서는 protobuf 스키마를 미리 알고 있어야 한다는 단점이 있다. json txt 의 겨웅 name 이라는 key 가 같이 전송되니 몰라도 되서 편안하다.
즉, A 는 이름이구나…를 바로 알 수 있지만 gRPC 는 모른다. 어쨌든 내부망에서 서로 통신할 떄는 어떤 스키마인지 미리 알고 있기 때문에 이진포멧으로 주고받아도 괜찮다.
이제 protobuf 를 사용해서 전송하게된다면 기존 21 bytes(json txt) -> 5 bytes(protobuf) 로 페이로드 크기가 훨씬 작아지니 네트워크 전송량도 줄어들고, 응답속도도 빨라질 것이다. 이와 관련한 실험결과를 가져왔다. https://auth0.com/blog/beating-json-performance-with-protobuf
보통 대부분 non-compressed json 로 통신하고 있는데, protobuf 로 바꾸면 json 대비 934ms -> 720ms 로 꽤 큰 응답속도 향상이 있다고 한다!
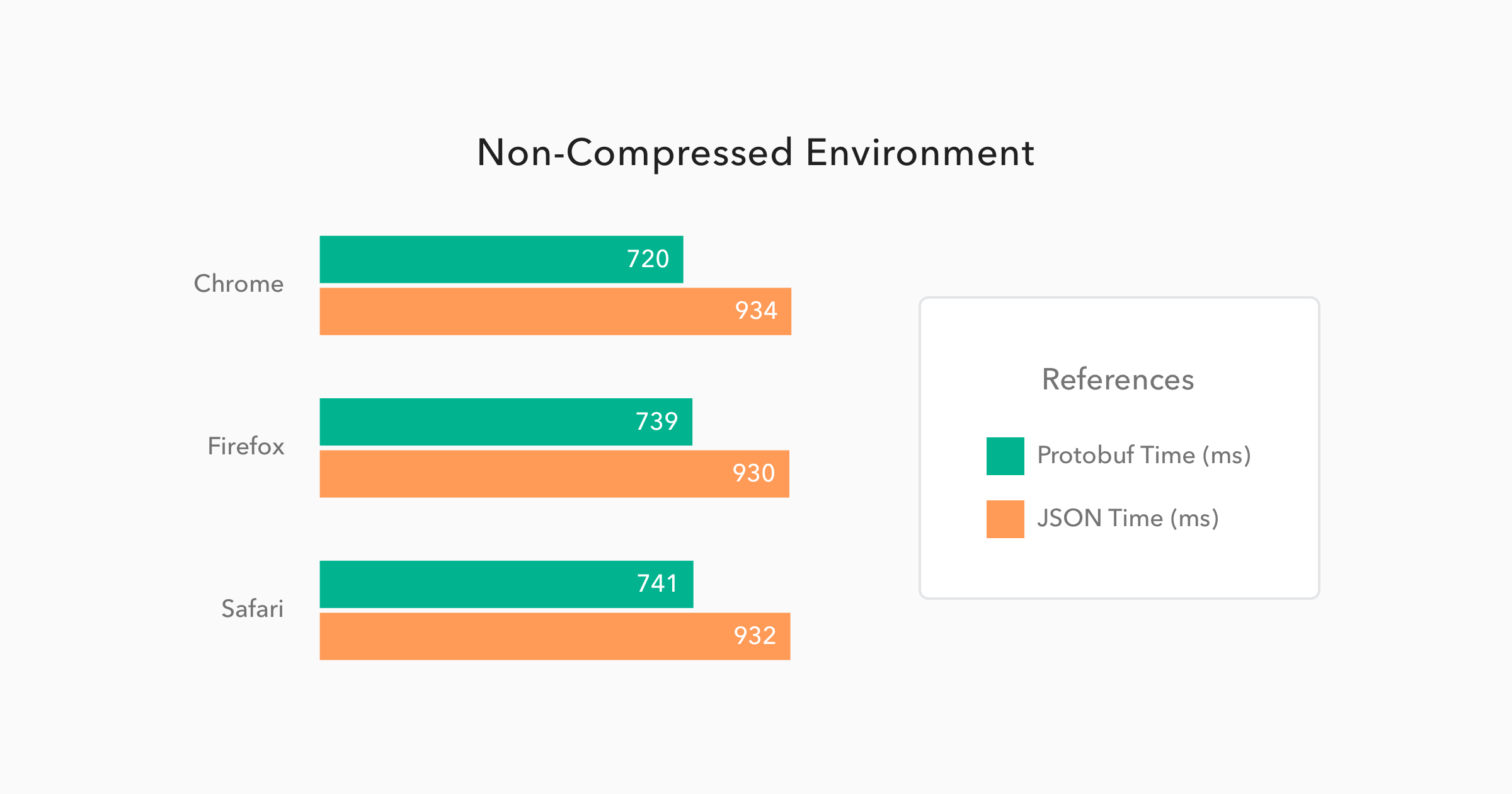
reference from https://auth0.com/blog/beating-json-performance-with-protobuf
RPS + p90 딜레이 결과 확인
gRPC 는 좀 귀찮아진다. protobuffer 코드 생성단계를 거쳐야 하고, 디버깅도 어렵다. 클라이언트, 서버 둘 다 동일한 스키마를 공유해야하고 기존 웹 상에서 따로 지원해줘야한다. 그래서 서버간 통신시 성능적 이점은 확실하니 내부망에서 대용량 데이터를 주고받을 때는 아주 유리하다.
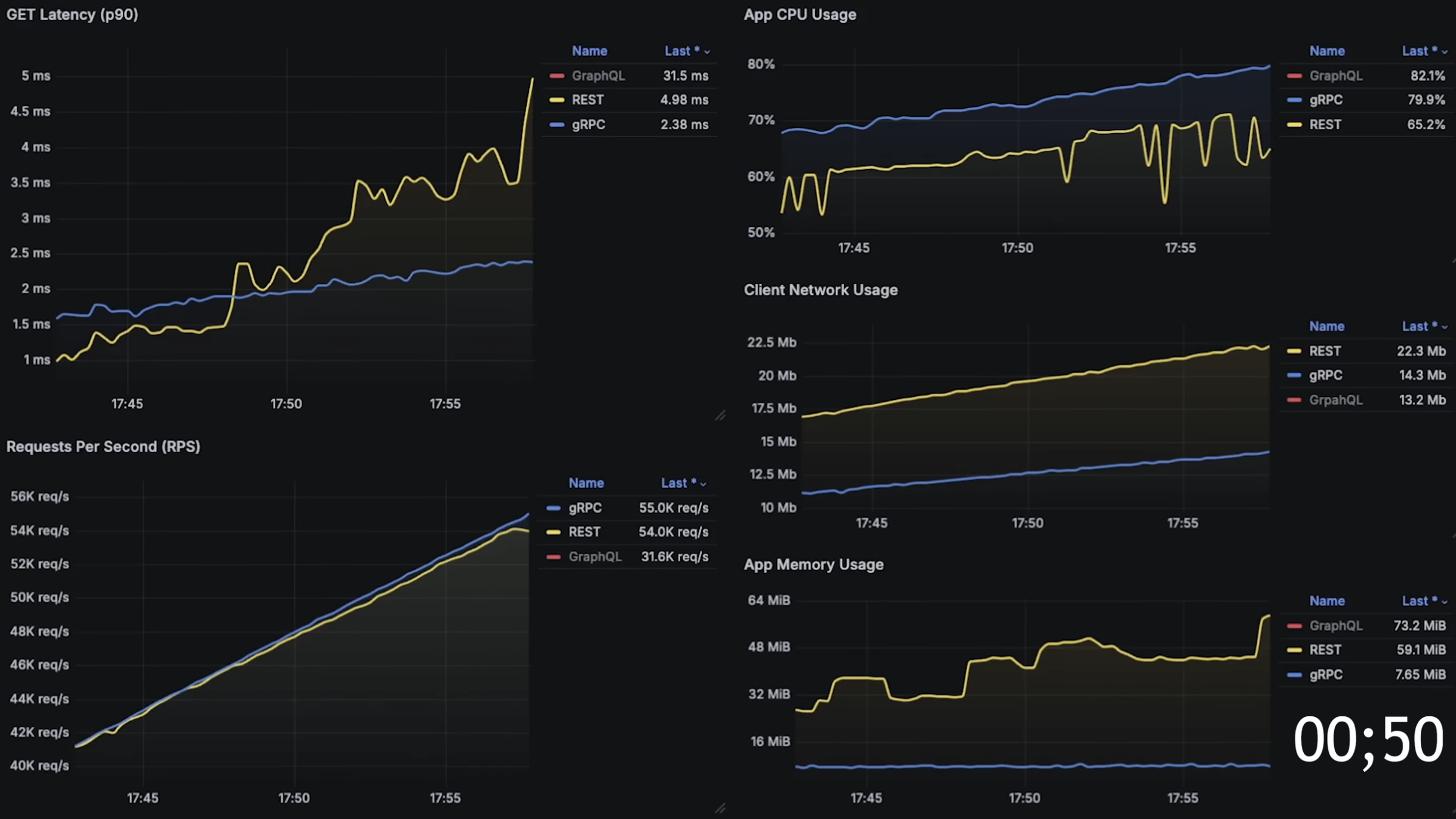
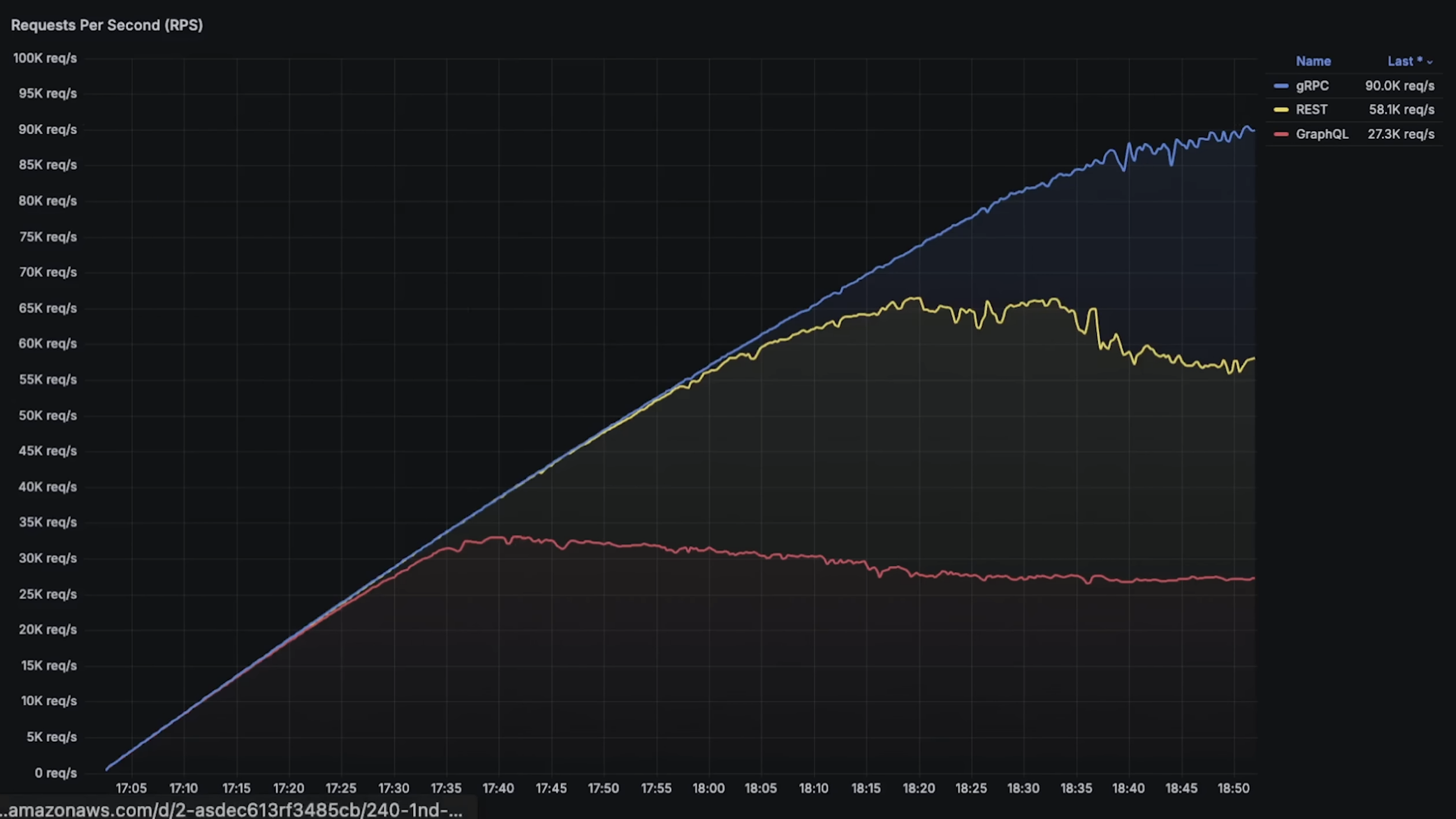
- reference : https://www.youtube.com/watch?v=uH0SxYdsjv4
레퍼런스 들어가서 보면 진짜 인상깊다. RTS 를 천천히 늘려가면서 p90 딜레이와 cpu 사용량을 측정한 결과를 보는데 초반부에는 40% 미만인 낮은 부하조건에서 REST API 가 gRPC 보다 더 낮은 딜레이를 보여준다. 아마도 gRPC 가 내부적으로 HTTP/2 + protobuf 직렬화/역직렬화 오버헤드가 있어서 그런 것 같다.
여기보면 초당 핸들링 가능한 요청 수를 비교하는 표인데 gRPC 가 압도적으로 높다. 어느 순간부터 많은 요청을 주고받을 때는 gRPC + Protobuf 조합이 아주 유리하다. 작은 수의 요청을 서로 주고받을 떄는 그냥 REST API 쓰면 됨. 만약에 진짜 매우매우 많은 수 까지 핸들링해야한다면 거의 초당 9만건 요청을 처리하고있는(REST API 에 비해 약 1.7배 이상 핸들링) gRPC 를 쓰는게 맞다.
- reference : https://www.youtube.com/watch?v=uH0SxYdsjv4
These days, gRPC is often used for both external and internal network communication. I heard that it can reduce payload size with a compact binary format. Since it seemed like it could help with performance optimization, I decided to look into gRPC, even though I usually only used REST APIs.
How the internal binary structure of protobuf works
gRPC is RPC using HTTP/2 + Protobuf. RPC simply means remotely executing a specific function on a server. The reason gRPC is used a lot these days is that it can reduce payload size. Let us directly calculate how compactly the JSON below can be transmitted when it is sent as protobuf.
{
"name": "A",
"age": 30,
}
If this JSON is transmitted as-is, the keys and values become 21 bytes when converted to bytes. Now define a protobuf schema.
message Person {
string name = 1;
int32 age = 2;
}
If you look at the gRPC HEX dump, it appears like below.
0A 01 41 | 10 1E
The really interesting parts here are 0A and 10. In the protobuf serialization format, each field is stored as a key-value pair. The key stores the type and field number together, and it is calculated like below.
key = (field_number << 3) | wire_type
wire_type is literally the type, and there is a matching table here: https://developers.google.com/protocol-buffers/docs/encoding#structure. You can look at that and apply bit operations according to the type. For string, the wire type is 2, length-delimited. For int32, it is 0, varint. If the lower 3 bits are 2, you can think of it as also carrying length information. So the name field is stored as (1 << 3) + 10(2) = 1010(2) = 0A(16). If you read it as binary, it means field 1 has type 010, which is string. If the field number is 8, it becomes 1000 000, and when wire type 2 is combined, it becomes 1000 010. Converted to hex, that becomes 42.
Then what happens if the field number is very large? It did not seem like the key could always fit in 8 bits, so I looked it up. It is stored by splitting the key into multiple bytes using varint encoding. Varint stores data as 7 bits + 1 continuation bit. So even very large numbers can be split across multiple bytes. The first key byte appears with the continuation bit set to 1, the second key byte has the continuation bit set to 0, and the actual value starts after that.
Now we know that 0A 01 41 means a string of length 1, 'A'. Next, look at 10 1E. 10(16) is 0001 0000(2), so the field number is 10(2) = 2, and the wire type is 0, meaning it is an integer. This one does not have a separate length, so the value appears immediately. 1E(16) is 30(10), so we know that age is 30.
In the end, the payload transmitted through gRPC is 0A 01 41 10 1E, and only 5 bytes are enough to represent the meaning. The downside is that it is hard for a human to read in the middle. So what value is string 'A'? To know that, you need to already know the protobuf schema. With JSON text, the key name is transmitted together, so it is comfortable even if you do not know the schema beforehand.
In other words, with JSON you can immediately tell that A is a name, but with gRPC you cannot. Still, when services communicate with each other inside an internal network, both sides already know the schema, so exchanging a binary format is fine.
If protobuf is used, the payload size decreases from 21 bytes for JSON text to 5 bytes for protobuf, so network transfer amount decreases and response speed should improve. I brought an experiment related to this: https://auth0.com/blog/beating-json-performance-with-protobuf
Most systems usually communicate with non-compressed JSON. According to the result, changing to protobuf improved response speed from 934ms to 720ms compared to JSON, which is a fairly large improvement.
reference from https://auth0.com/blog/beating-json-performance-with-protobuf
Checking RPS + p90 delay results
gRPC becomes a bit more cumbersome. It requires a protobuf code generation step, and debugging is harder. The client and server both need to share the same schema, and additional support is needed for the existing web side. Still, the performance advantage for server-to-server communication is clear, so it is very useful when exchanging large amounts of data inside an internal network.
- reference: https://www.youtube.com/watch?v=uH0SxYdsjv4
The reference is genuinely impressive. It gradually increases RTS and measures p90 delay and CPU usage. In the early part, under low-load conditions below 40%, REST API shows lower delay than gRPC. This is probably because gRPC has internal HTTP/2 + protobuf serialization/deserialization overhead.
There is also a table comparing how many requests can be handled per second, and gRPC is overwhelmingly higher. From a certain point, when many requests are exchanged, the gRPC + Protobuf combination becomes very advantageous. If only a small number of requests are exchanged, just use REST API. If you really need to handle a very large number of requests, gRPC is the right choice because it handles almost 90,000 requests per second, about 1.7x more than REST API.
- reference: https://www.youtube.com/watch?v=uH0SxYdsjv4