Intro
기존에 저희는 Mysql 를 main db 로, 멀티프렌차이즈를 목표로 운영하다보니 여러 다양한 스키마들이 필요했고 이를 위한 Mongodb 를 secondary db 로 운영하고 있었습니다. 그리고 신규 피처로 대량의 회원추출을 진행하기 위해 mysql slave 를 보는 것이 아닌, cdc 를 통해서 Mongodb 에 회원정보(주문, 메뉴, 스토어, 프렌차이즈, 약관, 회원, 상세정보들 etc. )를 upsert 하는 작업을 진행하고 있습니다. 이 과정에서 여러가지 조건들의 테이블을 단일 docs 로 합치게 된다면 mysql 에서 처럼 join 굳이 안해도 되기때문에 빠르게 조회가 가능해 집니다. 또한 아주 무거운 통계 API 는 통계집계용 DB 를 따로 보게 함으로써 기존 DB 에 부하를 줄일 수 있게 되었습니다(물론 slave db 딸깍으로 분산이 가능합니다).
정기배치가 아닌 CDC 로 진행한 이유는, 나중에 현재 secondary db 로 사용중인 mongodb 를 주문정보의 메인DB 로 사용하자라는 요구사항이 있어서 통계성 배치보다 CDC + ETL denormalization 으로 진행하게 되었습니다. 즉 의존성 최적화가 아니라 저장소 전환 가능성을 고려한 아키텍처 선택이었습니다.
그래서 Debezium server 을 사용하여 Mysql binlog 를 cdc 하고, 이를 Redis Stream 으로 보내고, 별도 sink pod 에서 Redis Stream 해당 토픽 읽고 Mongodb 에 upsert 하는 구조로 진행하고 있습니다.
OLAP 에는 https://medium.com/@simeon.emanuilov/mongodb-vs-clickhouse-for-olap-1e430a40ade8 ClickHouse 가 Big Data Query 에 좀 더 좋다고는 하네요. 예로 createdAt 같은 칼럼을 상대로 10월 데이터 조회하면 ClickHouse 가 더 빠르다고합니다.
이 과정을 정리되지 않은 기록으로 우선 남깁니다.
Debezium Server CDC
- kafka 없이 일반 debezium server 로 진행
- reference: https://debezium.io/documentation/reference/3.2
- https://debezium.io/documentation/reference/stable/operations/debezium-server.html
공식문서에서 보면 debezium.sink.type 설정이 aws 키네시스밖에 없어서 다른거 확인 중… stream 을 꼭 써야하나? kafka 말고 redis stream 도 지원하긴 하는데 source/sink 가 stream -> mongodb 있는지 봐야함.
- kafka stream → mongodb sink connector 은 있고 redis stream → mongodb sink connector 은 없음… 별도의 pod 를 띄워서 redis stream key 읽고 mongodb 에 upsert 하는 로직을 작성해야할 것 같다.
https://tech.kakaopay.com/post/kakaopaysec-mongodb-cdc/#4-consumer-group-생성-및-offset-설정 카카오페이에서는 kafka sink connector 사용함. 우리는 redis stream 쓰기때문에 별도로 만들어야함.
- debezium server → redis stream 설정값 공식 reference
- https://debezium.io/documentation/reference/2.7/operations/debezium-server.html#_redis_stream
- django 통해서 postgresql → mongodb 직접 sink 한 오픈소스. 공식으로 지원하는게 아니라 그냥 참고용. https://github.com/maqboolthoufeeq/cdc_debezium
- https://dev.to/maqboolthoufeeq/change-data-capture-cdc-with-debezium-server-no-kafka-django-postgres-mongodb-example-m0h
- Mysql → Debezium Server → Redis Stream 의 프로세스 소개
- Snapshots
- Debezium Server 가 동작할 때 현재 SQL server 상태의 스냅샷을 찍음. default가 INITIAL
- recovery, custom, initial_only, etc.
- 그래서 어느 테이블을 Capture 할거야? 정할 수 있음.
table.include.list파라미터 값으로
- insert sql 테스트. insert 후 1 증가 확인
ghkdqhrbals@ip-172-30-1-90 debezium-server % redis-cli --json XREVRANGE mysql_sink.gyumin.users + - COUNT 1 | jq -r '.[0][1][1] | fromjson | .payload.after.id'30001ghkdqhrbals@ip-172-30-1-90 debezium-server % redis-cli --json XREVRANGE mysql_sink.gyumin.users + - COUNT 1 | jq -r '.[0][1][1] | fromjson | .payload.after.id'30002
- 페이로드 확인
- payload(insert 는 before 없고 update 는 before 존재. + db & table 묶고 분기하여 mongodb upsert 하면 될 듯)
payload
... "payload": { "before": null, "after": { "id": 30002, "name": "테스트용 유저", // ... }, "source": { "version": "3.2.0.Final", "connector": "mysql", "name": "mysql_sink", "ts_ms": 1755138551000, "snapshot": "false", // 이거는 initial 단계에서 추가된 게 아니라 이후 cdc 한거임. "db": "gyumin", "sequence": null, "ts_us": 1755138551000000, "ts_ns": 1755138551000000000, "table": "users", "server_id": 1, "gtid": null, "file": "binlog.000002", "pos": 7114433, "row": 0, "thread": 385, "query": null }, "transaction": null, "op": "c", // c(insert). u(update), d(delete), r(read), t(truncate) // 초기에 db 읽어와서 redis stream 로드시킬 떄 r 로 들어감. "ts_ms": 1755138551799, "ts_us": 1755138551799549, "ts_ns": 1755138551799549000 }
source binload 세팅
// source binload 세팅 "source": { "version": "3.2.0.Final", // 2025.08.17 에 stable 한 최신 버전임. "connector": "mysql", "name": "mysql_sink", "ts_ms": 1755138551000, // 소스 이벤트 시각(ms). MySQL의 binlog 이벤트 타임스탬프 기반 "snapshot": "false", // 스냅샷 여부: true(기존 db 에 있던 rows 읽어올 때), false(실시간 cdc) "db": "gyumin", "sequence": null, "ts_us": 1755138551000000, // binlog 해당 이벤트 시간 "ts_ns": 1755138551000000000, "table": "users", // cdc 한 테이블 "server_id": 1, // mysql server id. 이거 값을 config 에서 우리가 설정가능 "gtid": null, // GTID 모드 사용 시 해당 트랜잭션의 GTID. 비활성화면 null "file": "binlog.000002", // 이벤트를 담고 있는 binlog 파일명 "pos": 7114433, // 위 binlog 파일 내 오프셋. debezium server 재시작하면 여기서부터 다시 cdc 함. "row": 0, // insert values 2개면 row 0, 1 로 나뉨. "thread": 385, // mysql db 세션의 id "query": null // ddl 쿼리. dml 에서는 null 로 표시함. 이거는 insert 한거라 null }update 시 페이로드 체크.
전체 row 변경점이 기록되기때문에 upsert 치기 좋긴 함. 변경된 부분만 binlog 에 기록되는게 아닌. mysql 에선
SHOW VARIABLES LIKE 'binlog_row_image';이거 FULL 이면 전/후 row 변경점을 다 기록함. postgresql 에서는 wal_level=logical 이랑 비슷함."payload": { "before": { "id": 30000, "name": "테스트용", // ... }, "after": { "id": 30000, "name": "테스트용 변경", // ... }binlog 오프셋 체크
HGETALL metadata:debezium:offsets{ "ts_sec": 1755155084, "file": "binlog.000002", "pos": 7117146}
설정 reference : https://redis.io/docs/latest/integrate/write-behind/reference/debezium/mysql/
# SINK SETTINTGS
debezium.sink.type=redis
debezium.sink.redis.address=localhost:6379
debezium.sink.redis.db.index=0
# SOURCE SETTINGS
# reference=https://redis.io/docs/latest/integrate/write-behind/reference/debezium/mysql/
debezium.source.connector.class=io.debezium.connector.mysql.MySqlConnector
debezium.source.database.server.id=111
debezium.source.database.dbname=gyumin
debezium.source.database.hostname=localhost
debezium.source.database.port=3306
debezium.source.database.user=root
# debezium.source.databbase.password=
debezium.source.snapshot.mode=initial
# <DB_NAME>.<TABLE_NAME> 으로 테이블 지정함. 그리고 아래 라인 regex 적용으로 ',' separate 시키기때문에 해당 라인 옆에 주석 추가하면 미동작.
debezium.source.table.include.list=gyumin.orders,gyumin.users
# 이건 column.include 옵션으로 칼럼단위 cdc 할 때 사용. 지금은 table 단위 전체 cdc 보기때문에 해당 설정값 미필요.
debezium.source.skip.messages.without.change=true
# binlogs n초 주기로 읽어와서 redis stream 에 밀어넣음. 0으로 설정하면 오자마자 넣는거
debezium.source.offset.flush.interval.ms=1000
# 어디까지 binlog sink 되었는지는 redis 에 저장하도록 함
debezium.source.offset.storage=io.debezium.storage.redis.offset.RedisOffsetBackingStore
# <prefix>.<dbName>.<tableName> key 로 stream 에 쌓임
debezium.source.topic.prefix=cdc
# cdc 할려는 테이블의 ddl 이력을 저장함
debezium.source.schema.history.internal=io.debezium.storage.redis.history.RedisSchemaHistory
증분 스냅샷
- 이건 cdc 할 테이블 나중에 추가할 떄 사용. 해당 테이블만 초기 rows 읽고 initialize 할 때 사용한다.
- https://debezium.io/blog/2021/10/07/incremental-snapshots/
- https://debezium.io/documentation/reference/stable/connectors/mysql.html#debezium-mysql-incremental-snapshots
- 트릭을 이용하는건데(공식에서 이렇게 말함) 아무 테이블 하나 만들고
.<table> 을 table.list 추가한 뒤 실행. 해당 테이블에 insert 쿼리 아래와 같이 전송하면 debezium 이 이 테이블 읽고있다가 스냅샷 쿼리 인지 후 테이블들을 청크단위 스냅샷 진행한다.
# 증분 스냅샷 명령용 테이블
CREATE TABLE db_schema.dbz_signal (
id VARCHAR(64) PRIMARY KEY,
type VARCHAR(32) NOT NULL,
data VARCHAR(2048) NULL
);
# debezium server property 에 위의 테이블 캡처하도록 설정. + 추가할 테이블도 바라보게. e.g. new_schema.users
# new_schema.users 이러이러한 테이블 스냅샷 가져와서 initialize 해라라고 명령하는 쿼리
INSERT INTO db_schema.dbz_signal (id, type, data)
VALUES (
'signal-1',
'execute-snapshot',
'{"data-collections":["new_schema.users"],"type":"incremental"}'
;
이러면!! 스트림이 생성되고
XLEN mysql_sink.new_schema.users 로 크기 및 실제 페이로드를 확인해보면 new_schema 에 들어있던 rows 들이 전부 스트림에 로드된 것을 확인할 수 있다.
Mysql datetime to millis 알고있어야함.
reference : https://debezium.io/documentation/reference/stable/connectors/mysql.html#mysql-temporal-types
DATETIMEwith a value of2018-06-20 06:37:03becomes1529476623000.
정상동작 확인되었으니 해당 건 도커라이징 후 외부 환경변수 secret 세팅과 pod 로 로드하는 cicd 파이프라인 및 모니터링 설정 필요!
CDC 안정화
- redis commandTimeout > redis XGROUPREAD pollTimeout 설정해줘야 됨. pollTimeout 이 XGROUPREAD 로 읽을 때 command 대기시간 설정하는건데 이 값은 redis connection 자체관리 commandTimeout 값보다 작아야한다.
- 싱크실패 dbms row 재처리 로직 필요
- 진짜 문제는 만약 주문테이블 싱크할 때 하나가 실패했다고 가정한다면 꽤 까다롭다. PEL 에 들어있는 해당 주문을 다시 싱크 해주어야하는데 딱 이때 마침 해당 주문이 업데이트되면 PEL 재처리할 떄 덮어씌워진다. A –> B –> C 되어야하는데, A -x-> B 가 실패하고, 그 사이에 C 가 들어오면 A -> C 로 되어버린다. 그래서 PEL 재처리할 때 해당 row 가 업데이트된게 있는지 체크하는 로직이 필요하다. 만약 해당 row 가 업데이트 되었다면 재처리할 떄 무시한다(이미 최신의 값으로 업데이트되었기 때문). 이떄 row delete 된 경우를 생각해야한다. row 가 삭제되면 언제 삭제되었는지 시간을 따로 남겨서 재처리 메세지 시간이랑 비교해서 우선권이 있는 메세지를 적용해야하는데 이 부분은 우리 기본정책이 소프트 delete 라 크게 신경안써도 될 듯! 종합하면 row 업데이트 시간을 보고 재처리 메세지 시간보다 최신이면 재처리 무시, 아니면 재처리 진행한다.
구현한 Sink (CDC + ETL) 데이터 적재 모듈 관련 내용정리
DB(MySQL) 변경을 Debezium CDC 로 Redis stream 적재 및 stream key 구독/수신하여 MongoDB 도메인 문서로 적재하는 모듈에 대한 설명.
테이블 단위로 커넥터를 추가해 mysql 테이블을 mongodb 도메인 문서로 매핑/적재하는 구조.
전체 흐름
CDC, ETL 모듈 배포
git actions 기존 프렌차이즈 별 수동배포에 공통모듈 배포하는 방식 추가 후 개별 모듈(debezium, sink module) CI/CD 파이프라인 구축. 주요 파라미터(db, redis, mongo, quarkus params, etc.) 는 deploy.yaml 에 envset 으로 linux 로컬 export env 가 치환되어 주입하도록 설정.
Debezium Server CDC
Debezium Server 가 MySQL binlog 를 읽어 변경 이벤트를 JSON payload로 redis stream 에 전송
ETL 모듈
1) Row 데이터 클래스 정의
- 위치: order-hub-sink/src/main/kotlin/…/connector/
/ - Debezium after/before 스냅샷을 그대로 담는 용도
- 가능한 null 허용으로 선언(ddl 칼럼 nullable 로 변경될 수도 있어서)
2) Mongo 도메인 문서 정의(E : SinkClass)
- 위치: order-hub/src/main/kotlin/…/domain/sink/
/ - sinkInfo(mysqlId, franchiseCode, sinkedAt) 포함
- 정규화 풀려면 upsert, toEntity 구조 리모델링
3) 싱크 커넥터 구현
- @Component class XxxSinkConnector(mongoTemplate: MongoTemplate)
- SinkConnector<{Row}, {Entity}> 상속(이 때 Row 는 mysql 테이블 읽는 중간 클래스, Entity 는 mongodb @Document)
- typeRef: TypeReference<DebeziumMessage
>() 구현
- mysqlTableName 과 collectionName 지정
- toEntity(row, franchise)에서 매핑 작성
- keyQuery(row, franchise)에서 upsert/remove 키 작성
참고: 단순 테이블은 findAndReplace(upsert)로 충분. 문서 내부 별도로 비정규화한 아이템 배열을 수정해야 하는 경우(예: order_items)에는 안전한 필드 단위 .set 사용을 고려
- SinkConnector<T, E : SinkClass>
- handle(): DebeziumMessage 파싱, op(c/r/u/d) 에 따라 upsert/remove 수행
- toEntity(row, franchise): Row -> Mongo 도메인 문서 변환
- keyQuery(row, franchise): upsert/remove 키 쿼리 작성(보통 sinkInfo.mysqlId + sinkInfo.franchiseCode)
- mysqlTableName: 담당 MySQL 테이블명 (ex. “orders”, “order_items”)
- collectionName: 대상 Mongo 컬렉션명 (ex. “sink_orders”)
- SinkConnectorFinder: mysqlTableName 기준으로 적절한 커넥터 선택
4) 라우팅 등록
- @Component 만 달면 SinkConnectorFinder 가 자동 수집하여 mysqlTableName 으로 라우팅
5) 테스트 작성
- Kotest StringSpec + Testcontainers(MongoDB)
- DebeziumMessage 래퍼를 직접 생성해 c/u/d 케이스를 시뮬레이션
- 멀티 프랜차이즈(FranchiseCode) 격리, 배열 추가/갱신/삭제, Null/극단값 등 엣지 케이스 검증
6) Order Hub Sink 모듈이 SinkBindingsConfig 에서 설정한 redis stream 구독, 메시지 수신 7) Debezium JSON을 파싱하여 테이블별 SinkConnector 로 라우팅 8) 각 커넥터가 Row(테이블 스키마) -> 도메인 Sink 문서로 매핑하고 MongoDB에 upsert/remove 수행 9) franchiseCode + mysqlId 를 문서의 sinkInfo 에 보관. 동일한 mysqlId 라도 가맹별로 격리 저장되어있음.
하다보니 생긴 중요한 이슈 및 팁
- redis stream 에 메시지 적재하는 속도보다 sink 처리 속도가 느려서 메모리 부족으로 OOM 발생함. 그래서 sink 시 binlog -> redis stream 적재 유량제어 할 수 있는 옵션을 사용하면 된다. 이거 설정할 땐
redis-cli CONFIG SET maxmemory 4096mb로 redis 서버의 max memory limit 먼저 1차 설정해주고 난 뒤 적용하니까 잘됨. 그냥 기존 0 (unlimited) 상태에서 이 옵션만 주면 제대로 적용이 안됨. (관련 공식 레퍼런스나 올라온 이슈 찾아봐도 없어서 내 추측으로는 redis maxmemory unlimited 0 상태에서는 debezium server limit 옵션이 무시되는 것 같음.) maxmemory-policy 는 noeviction 으로 설정해두었음.debezium.sink.redis.memory.limit.mb=512(512MB 로 제한)debezium.sink.redis.memory.threshold.percentage=85(85% 도달 시점부터 유량제어 시작)
- debezium.sink.redis.memory.limit.mb=${DBZ_REDIS_MEMORY_LIMIT_MB:512}
- debezium.sink.redis.memory.threshold.percentage=85 reference
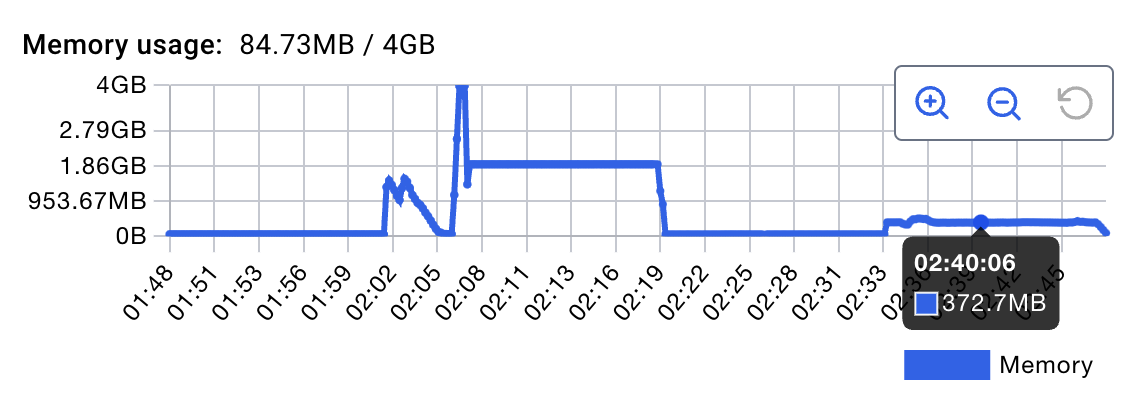
아래보면 설정이전에는 메모리 4G 찍고 key 제거. 설정이후 512 / 85% 로 제한되니까 메모리 400 대 언더로 유지되는거 확인.
- 어떤 stream 을 읽을 지 미리 하드코딩해서 세팅해놓기보단 특정 prefix( mysql_sink.* ) 로 시작하는 stream 을 동적으로 연결해서 읽도록 설정하는게 운영에 훨씬 유리함. 그래서 스케줄러로 매 초마다 stream key 목록을 조회해서 읽도록 설정. 또 stream read 커넥션 맺을 필요 없으니까 인메모리 리스트로 관리.
- stream 에 적재된 mysql 데이터를 읽는건 기존에 벌크로 읽고 있었지만 결국 읽어와서 mongodb upsert 를 하나씩 히고있었고 꽤 병목이였음. 단건처리 물론 속도는 n ms 이내 이지만 이게 누적되면 꽤 커지기 때문에 결국 병목이였음. 또한 개별 메세지 ack, delete, pending 관리또한 오버헤드라 전체적으로 하나의 청크단위처리가 필요했다. stream -> 100 read -> buffer 적재 -> 100개 차면 bullk mongodb flush() & redis bulk ack, delete. 하도록 수행. 100개 다 안차도 1초에 한번씩 flush() 하도록 스케줄러 추가. 이러니까 훨씬 안정적이고 빠름. 기존엔 단건 메세지 처리에 1.3 ~ 1.5 ms 소요됬는데 약 100개처리에 평균 27ms 정도니까 약 0.27 ms 거의 5배 빨라짐. 목표는 네트워크 라운드 트립 비용 줄었기였고 결과는 예상한 대로 나왔다. 아래는 AOP 붙여서 bulkHandle() 메서드 실행시간 찍은 로그.
2025-09-26T02:48:01.890+09:00 INFO 96441 --- [fooddash-domain] [ virtual-246] [\] c.f.o.connector.SinkConnector : bulkHandle called with 100 records for table menus
SinkConnector.bulkHandle(..) 실행 시간: 26.672 ms
2025-09-26T02:48:01.926+09:00 INFO 96441 --- [fooddash-domain] [MessageBroker-2] [\] c.f.o.connector.SinkConnector : bulkHandle called with 12 records for table menus
SinkConnector.bulkHandle(..) 실행 시간: 4.947 ms
2025-09-26T02:48:01.984+09:00 INFO 96441 --- [fooddash-domain] [ virtual-246] [\] c.f.o.connector.SinkConnector : bulkHandle called with 100 records for table menus
SinkConnector.bulkHandle(..) 실행 시간: 26.582 ms
2025-09-26T02:48:02.027+09:00 INFO 96441 --- [fooddash-domain] [MessageBroker-8] [\] c.f.o.connector.SinkConnector : bulkHandle called with 25 records for table menus
SinkConnector.bulkHandle(..) 실행 시간: 7.496 ms
2025-09-26T02:48:02.079+09:00 INFO 96441 --- [fooddash-domain] [ virtual-246] [\] c.f.o.connector.SinkConnector : bulkHandle called with 100 records for table menus
SinkConnector.bulkHandle(..) 실행 시간: 27.653 ms
2025-09-26T02:48:02.127+09:00 INFO 96441 --- [fooddash-domain] [MessageBroker-8] [\] c.f.o.connector.SinkConnector : bulkHandle called with 1 records for table menus
SinkConnector.bulkHandle(..) 실행 시간: 1.658 ms
- 종합하면 메모리 기반이기때문에 데이터 유실이 있을 수 있음. 유실 최소화하기위해 noeviction 정책 설정 및 mysql->redis 유량제어 설정. history 및 offset redis 에 기록되어 저장되기때문에 debezium server 재시작시점부터 다시 cdc 가능. 진짜 만약에 이 binlog 어디까지 읽었는지 offset 마저 날라가도 처음부터 스냅샷해도 됨. redis -> mongodb 에 멱등성이 보장되기 때문에.(만약 sink 된 문서의 수정이 있다면 수정됨=true 로 해놓고 ETL 모듈에서 upsert 할 때 true 면 업데이트 안하도록 처리하든 아니면 따로 read 전용 sink 문서로 관리하든 데이터 운영정책에 맞게 처리하면 됨.)
Appendix
새로운 테이블 추가 시 체크리스트
- Row 데이터 클래스 생성 (snake_case, null 허용, BigDecimal/OffsetDateTime 등)
- 도메인 문서(SinkClass 를 상속받는) 생성
싱크커넥터 구현 및 SinkBindingsConfig 에 @Bean 등록이거 다이나믹하게 sink_mysql.* prefix 로 시작하는 stream 을 읽도록 변경해서 유지보수 편하게 해놓음.- 비정규화 필요 시 OrderItem 참조(개별 upsert, toEntity).
- Kotest + Testcontainers 테스트 작성 (c/u/d, 멀티 프랜차이즈, 엣지 케이스)
- Debezium 스냅샷/시그널 전략 검토.(해당 테이블 기존 row 스냅샷 need? or not)
- 만약 need 하면 위 증분 스냅샷 전략 참고
- Debezium server application.properties 알아놓으면 좋은 규칙들
- line 끝에 주석달면 Regex 오류남.
- big decimal 은 debezium.source.decimal.handling.mode=string 으로 설정해야지 정확히 읽어옴.
- setup each table as
. - Debezium Server 설정에 맞춰 execute-snapshot 등 시그널을 사용해 특정 테이블 스냅샷 수행 가능
datetime debezium 내 변환
debezium server 은 mysql 시간 칼럼 타입에 따라 micro, milli, second 등 다르게 로딩함.

팀 내에서 datetime(2), datetime, timestamp 등 다양한 시간 타입을 쓰고있어서 debezium adaptive_seconds 모드로 변환적재했을 때 이게 micro, milli, second 중 뭔지 모르는 문제가 있음. 물론 기존 ddl 칼럼 타입을 보면 이게 뭔지 알 수 있지만 귀찮음. 2280 년까지는(정확히는 2286-11-20 17:46:40 UTC) 문제없는 방법이 있는데 그게 10자리 이하는 second, 11~13자리 milli, 14~16자리 micro 로 구분하는 방법임. 1970년 이전은 마이너스 표긴데 이것도 변환 가능함. 얘도 경계값이 초 단위가 1~10자리 적용되는 범위가 1653(1653-03-05 23:46:40 UTC)년도인데 사실 정말 과거의 정보를 가지고있어야한다는 요구사항이 없다면(db 에 이 값을 저장하고싶다가 아니면) 마이너스도 마찬가지로 abs 해서 적용하면 됨.
근데 정말 우리는 2280년 이후 값을 쓰지않나? 다시 보니까
9999년 12월 31일값을 쓰고 있음. 그래서 그냥time.precision.mode=connect로 설정하고 모든 타임 칼럼 타입 datetime(m) 으로 다 통일한 뒤 debezium 이 milliseconds 로 일괄설정하도록 유도하는게 좋을듯. 그러면 그냥 Long 타입 오면 생각안하고 milliseconds 판단 후 변환해주면 됨. (참고로 postgresql 일괄 microsecond 설정같은거 가능함. mysql 은 노가다 ㅜ)
본 모듈에 정의한 Rules
- sinkedAt 은 binlog event 발생시점이며, 본 모듈에서는 기존 문서의 sinkedAt 보다 빠른 sinkedAt 이 도착하면 그대로 sink 함. 이유는 select 쿼리 네트워크 비용을 줄이기 위함.
- sink 실패건은 1회에 한해 재시도함. 이후 성공여부 관계없이 pending & stream 에서 제거. 이후 정확한 데이터가 필요할 시 재처리 전략 변경 필요.
- sink 성공하면 stream 에서 제거하여 메모리 확보함.
- ex) Order 문서에 OrderItem 을 포함하도록 비정규화 시 Order 보다 OrderItem 이 먼저 생길 수 있음. 이를 고려해야함.
- Row 데이터 클래스는 최대한 null 허용으로 선언하여 이후 RDBMS DDL 변경에 유연하게 대응.
Intro
Previously, we used MySQL as the main DB. Because we were operating with multi-franchise support in mind, we needed many different schemas, and we were also operating MongoDB as a secondary DB for that purpose. For a new feature that extracts a large number of members, instead of reading from a MySQL slave, we are using CDC to upsert member information into MongoDB. This includes orders, menus, stores, franchises, terms, members, detailed information, and so on. If tables with various conditions are merged into a single document during this process, queries become faster because there is no need to join like in MySQL. Also, very heavy statistics APIs can read from a separate statistics aggregation DB, reducing load on the existing DB. Of course, a slave DB can also distribute this load easily.
The reason I chose CDC instead of a scheduled batch was that there was a future requirement to use the current secondary MongoDB as the main DB for order information. So I chose CDC + ETL denormalization rather than a statistics batch. In other words, this was not just dependency optimization, but an architecture choice that considered the possibility of changing the storage.
So the current structure is: use Debezium Server to CDC MySQL binlog, send it to Redis Stream, and have a separate sink pod read the Redis Stream topic and upsert into MongoDB.
For OLAP, this post says ClickHouse is better for big data queries. For example, when querying October data against a column like
createdAt, ClickHouse is said to be faster.
I am leaving this process as an unorganized record first.
Debezium Server CDC
- Proceeded with plain Debezium Server without Kafka.
- reference: https://debezium.io/documentation/reference/3.2
- https://debezium.io/documentation/reference/stable/operations/debezium-server.html
In the official docs,debezium.sink.typeonly seemed to show AWS Kinesis, so I was checking other options. Do we really need to use stream? Redis Stream is supported besides Kafka, but I need to check whether there is source/sink support for stream -> MongoDB.
- There is a Kafka Stream -> MongoDB sink connector, but there is no Redis Stream -> MongoDB sink connector. It looks like we need to run a separate pod that reads Redis Stream keys and upserts into MongoDB.
KakaoPay uses a Kafka sink connector here: https://tech.kakaopay.com/post/kakaopaysec-mongodb-cdc/#4-consumer-group-생성-및-offset-설정. Since we use Redis Stream, we need to build it separately.
- Official reference for Debezium Server -> Redis Stream settings:
- https://debezium.io/documentation/reference/2.7/operations/debezium-server.html#_redis_stream
- Open source example that directly sinks PostgreSQL -> MongoDB through Django. It is not officially supported, so it is only for reference.
- https://github.com/maqboolthoufeeq/cdc_debezium
- https://dev.to/maqboolthoufeeq/change-data-capture-cdc-with-debezium-server-no-kafka-django-postgres-mongodb-example-m0h
- MySQL -> Debezium Server -> Redis Stream process
- Snapshots
- When Debezium Server runs, it takes a snapshot of the current SQL server state. The default is
INITIAL.- recovery, custom, initial_only, etc.
- You can decide which tables to capture with the
table.include.listparameter.
- Insert SQL test. Confirm that the id increases by 1 after insert.
ghkdqhrbals@ip-172-30-1-90 debezium-server % redis-cli --json XREVRANGE mysql_sink.gyumin.users + - COUNT 1 | jq -r '.[0][1][1] | fromjson | .payload.after.id'30001ghkdqhrbals@ip-172-30-1-90 debezium-server % redis-cli --json XREVRANGE mysql_sink.gyumin.users + - COUNT 1 | jq -r '.[0][1][1] | fromjson | .payload.after.id'30002
- Payload check
- Payload: insert has no
before, update hasbefore. It should be enough to branch by DB and table and then upsert into MongoDB. payload
... "payload": { "before": null, "after": { "id": 30002, "name": "테스트용 유저", // ... }, "source": { "version": "3.2.0.Final", "connector": "mysql", "name": "mysql_sink", "ts_ms": 1755138551000, "snapshot": "false", "db": "gyumin", "sequence": null, "ts_us": 1755138551000000, "ts_ns": 1755138551000000000, "table": "users", "server_id": 1, "gtid": null, "file": "binlog.000002", "pos": 7114433, "row": 0, "thread": 385, "query": null }, "transaction": null, "op": "c", "ts_ms": 1755138551799, "ts_us": 1755138551799549, "ts_ns": 1755138551799549000 }
- Payload: insert has no
Source binlog settings
"source": { "version": "3.2.0.Final", "connector": "mysql", "name": "mysql_sink", "ts_ms": 1755138551000, "snapshot": "false", "db": "gyumin", "sequence": null, "ts_us": 1755138551000000, "ts_ns": 1755138551000000000, "table": "users", "server_id": 1, "gtid": null, "file": "binlog.000002", "pos": 7114433, "row": 0, "thread": 385, "query": null }Check payload on update.
Since the entire row change is recorded, it is convenient for upsert. It is not only the changed part that is recorded in the binlog. In MySQL, if
SHOW VARIABLES LIKE 'binlog_row_image';isFULL, both before and after row changes are recorded. In PostgreSQL, this is similar towal_level=logical."payload": { "before": { "id": 30000, "name": "테스트용", // ... }, "after": { "id": 30000, "name": "테스트용 변경", // ... }Check binlog offset with
HGETALL metadata:debezium:offsets{ "ts_sec": 1755155084, "file": "binlog.000002", "pos": 7117146}
Settings reference: https://redis.io/docs/latest/integrate/write-behind/reference/debezium/mysql/
# SINK SETTINTGS
debezium.sink.type=redis
debezium.sink.redis.address=localhost:6379
debezium.sink.redis.db.index=0
# SOURCE SETTINGS
# reference=https://redis.io/docs/latest/integrate/write-behind/reference/debezium/mysql/
debezium.source.connector.class=io.debezium.connector.mysql.MySqlConnector
debezium.source.database.server.id=111
debezium.source.database.dbname=gyumin
debezium.source.database.hostname=localhost
debezium.source.database.port=3306
debezium.source.database.user=root
# debezium.source.databbase.password=
debezium.source.snapshot.mode=initial
# Specify tables as <DB_NAME>.<TABLE_NAME>. Since the line is split by regex with comma separation, adding a comment next to this line can break it.
debezium.source.table.include.list=gyumin.orders,gyumin.users
# Used when doing column-level CDC with column.include. Not needed now because we are doing table-level CDC.
debezium.source.skip.messages.without.change=true
# Read binlogs every n seconds and push them into Redis Stream. If set to 0, push immediately when they arrive.
debezium.source.offset.flush.interval.ms=1000
# Store how far the binlog was sunk in Redis.
debezium.source.offset.storage=io.debezium.storage.redis.offset.RedisOffsetBackingStore
# Streams are accumulated with the key format <prefix>.<dbName>.<tableName>.
debezium.source.topic.prefix=cdc
# Store the DDL history of the tables being captured.
debezium.source.schema.history.internal=io.debezium.storage.redis.history.RedisSchemaHistory
Incremental snapshots
- This is used when adding a CDC table later. It is used to read and initialize only the initial rows of that table.
- https://debezium.io/blog/2021/10/07/incremental-snapshots/
- https://debezium.io/documentation/reference/stable/connectors/mysql.html#debezium-mysql-incremental-snapshots
- It uses a trick, and the official docs call it that. Create any table, add
<db>.<table>totable.list, and run it. If you send an insert query like below to that table, Debezium reads it, recognizes that it is a snapshot query, and performs snapshots for the tables by chunk.
# Table for incremental snapshot commands.
CREATE TABLE db_schema.dbz_signal (
id VARCHAR(64) PRIMARY KEY,
type VARCHAR(32) NOT NULL,
data VARCHAR(2048) NULL
);
# Configure Debezium Server properties to capture the table above and also watch the table to be added, e.g. new_schema.users.
# Query that tells Debezium to snapshot and initialize a table such as new_schema.users.
INSERT INTO db_schema.dbz_signal (id, type, data)
VALUES (
'signal-1',
'execute-snapshot',
'{"data-collections":["new_schema.users"],"type":"incremental"}'
;
Then a stream is created.
If you check the size and actual payload with XLEN mysql_sink.new_schema.users, you can confirm that all rows in new_schema were loaded into the stream.
Need to understand MySQL datetime to millis
reference: https://debezium.io/documentation/reference/stable/connectors/mysql.html#mysql-temporal-types
DATETIMEwith a value of2018-06-20 06:37:03becomes1529476623000.
Since normal operation was confirmed, this now needs Dockerization, external environment variable secret setup, a CI/CD pipeline that loads it as a pod, and monitoring configuration.
CDC stabilization
redis commandTimeoutmust be greater than the RedisXGROUPREAD pollTimeout.pollTimeoutconfigures how long the command waits when reading withXGROUPREAD, and this value must be smaller than the Redis connection-levelcommandTimeout.- Logic is needed to reprocess DBMS rows when sync fails.
- The difficult part is a case where one order fails during order-table sync. The order in the PEL needs to be synced again, but if that order is updated at exactly that time, the PEL retry can overwrite it. It should go A -> B -> C, but if A -x-> B fails and C comes in between, it becomes A -> C. So when reprocessing from the PEL, logic is needed to check whether the row has been updated. If the row has already been updated, ignore the retry because it has already been updated to the latest value. Deleted rows also need to be considered. If a row is deleted, the deletion time should be stored separately and compared with the retry message time so that the message with priority is applied. Since our default policy is soft delete, this part probably does not need much attention. In summary, check the row update time. If it is newer than the retry message time, ignore the retry. Otherwise, proceed with reprocessing.
Notes on the implemented Sink data loading module, CDC + ETL
This module loads DB changes from MySQL into Redis Stream through Debezium CDC, subscribes to and receives stream keys, and loads them into MongoDB domain documents.
The structure adds connectors by table and maps/loads MySQL tables into MongoDB domain documents.
Overall flow
CDC, ETL module deployment
Added a common-module deployment method to the existing manual deployment per franchise in GitHub Actions, then built CI/CD pipelines for individual modules such as Debezium and the sink module. Main parameters such as DB, Redis, Mongo, and Quarkus params are configured so Linux local exported env values are substituted and injected through deploy.yaml as an envset.
Debezium Server CDC
Debezium Server reads MySQL binlog and sends change events as JSON payloads to Redis Stream.
ETL module
- Define Row data classes
- Location: order-hub-sink/src/main/kotlin/…/connector/
/ - Used to store Debezium
after/beforesnapshots as-is - Declare nullable as much as possible, because DDL columns may later change to nullable
- Location: order-hub-sink/src/main/kotlin/…/connector/
- Define Mongo domain documents,
E : SinkClass- Location: order-hub/src/main/kotlin/…/domain/sink/
/ - Include
sinkInfo(mysqlId, franchiseCode, sinkedAt) - If denormalization is needed, remodel the upsert and
toEntitystructure
- Location: order-hub/src/main/kotlin/…/domain/sink/
- Implement sink connectors
@Component class XxxSinkConnector(mongoTemplate: MongoTemplate)- Extend
SinkConnector<{Row}, {Entity}>. HereRowis the intermediate class read from the MySQL table, andEntityis the MongoDB@Document. - Implement
typeRef: TypeReference<DebeziumMessage<Row>>() - Specify
mysqlTableNameandcollectionName - Write mapping in
toEntity(row, franchise) - Write upsert/remove keys in
keyQuery(row, franchise) - Note: for simple tables,
findAndReplace(upsert)is enough. For cases where an item array denormalized inside the document needs to be modified, such asorder_items, consider safe field-level.set.
SinkConnector<T, E : SinkClass>handle(): parseDebeziumMessage, then upsert/remove depending onop(c/r/u/d)toEntity(row, franchise): convert Row -> Mongo domain documentkeyQuery(row, franchise): create the upsert/remove key query, usuallysinkInfo.mysqlId + sinkInfo.franchiseCodemysqlTableName: responsible MySQL table name, for example"orders"or"order_items"collectionName: target Mongo collection name, for example"sink_orders"
SinkConnectorFinder: selects the proper connector based onmysqlTableName
- Register routing
- If only
@Componentis attached,SinkConnectorFinderautomatically collects it and routes bymysqlTableName.
- If only
- Write tests
- Kotest
StringSpec+ Testcontainers with MongoDB - Create
DebeziumMessagewrappers directly and simulate c/u/d cases - Verify edge cases such as multi-franchise isolation by
FranchiseCode, array add/update/delete, null, and extreme values
- Kotest
- The Order Hub Sink module subscribes to and receives Redis Streams configured in
SinkBindingsConfig - Parse Debezium JSON and route it to each table’s
SinkConnector - Each connector maps Row, the table schema, into a domain Sink document and performs upsert/remove in MongoDB
- Store
franchiseCode + mysqlIdin the document’ssinkInfo. Even if the samemysqlIdexists, it is isolated and stored per franchise.
Important issues and tips found while implementing
- The sink processing speed was slower than the speed at which messages were loaded into Redis Stream, so OOM occurred due to memory shortage. To solve this, use options that can control the flow from binlog -> Redis Stream during sink. When configuring this, I first set the Redis server max memory limit with
redis-cli CONFIG SET maxmemory 4096mb, and then it worked well. If I only set this option while Redis was in the existing0unlimited state, it did not apply properly. I could not find an official reference or issue for this, but my guess is that the Debezium Server limit option is ignored when Redismaxmemoryis unlimited0. Themaxmemory-policywas set tonoeviction.debezium.sink.redis.memory.limit.mb=512debezium.sink.redis.memory.threshold.percentage=85
debezium.sink.redis.memory.limit.mb=${DBZ_REDIS_MEMORY_LIMIT_MB:512}debezium.sink.redis.memory.threshold.percentage=85reference
Before the setting, memory reached 4GB and keys were evicted. After limiting it to 512MB / 85%, memory stayed under the 400MB range.
Instead of hardcoding in advance which streams to read, it is much better operationally to dynamically connect to and read streams that start with a specific prefix such as
mysql_sink.*. So I configured a scheduler to query the stream key list every second and read them. Since there is no need to create a separate stream read connection, it is managed as an in-memory list.MySQL data loaded into streams was previously read in bulk, but eventually MongoDB upsert was done one by one, which became a bottleneck. Single-record processing was within n ms, but when accumulated, it became large. Individual message ack, delete, and pending management also added overhead, so chunk-level processing was needed overall. The flow became: stream -> read 100 -> load into buffer -> when 100 are accumulated, bulk MongoDB
flush()and Redis bulk ack/delete. Even if 100 are not filled, a scheduler flushes once per second. This became much more stable and faster. Previously, single-message handling took 1.3 to 1.5ms, but processing about 100 records averaged around 27ms, or about 0.27ms each, almost 5x faster. The goal was to reduce network round-trip cost, and the result came out as expected. Below is a log ofbulkHandle()execution time measured with AOP.
2025-09-26T02:48:01.890+09:00 INFO 96441 --- [fooddash-domain] [ virtual-246] [\] c.f.o.connector.SinkConnector : bulkHandle called with 100 records for table menus
SinkConnector.bulkHandle(..) execution time: 26.672 ms
2025-09-26T02:48:01.926+09:00 INFO 96441 --- [fooddash-domain] [MessageBroker-2] [\] c.f.o.connector.SinkConnector : bulkHandle called with 12 records for table menus
SinkConnector.bulkHandle(..) execution time: 4.947 ms
2025-09-26T02:48:01.984+09:00 INFO 96441 --- [fooddash-domain] [ virtual-246] [\] c.f.o.connector.SinkConnector : bulkHandle called with 100 records for table menus
SinkConnector.bulkHandle(..) execution time: 26.582 ms
2025-09-26T02:48:02.027+09:00 INFO 96441 --- [fooddash-domain] [MessageBroker-8] [\] c.f.o.connector.SinkConnector : bulkHandle called with 25 records for table menus
SinkConnector.bulkHandle(..) execution time: 7.496 ms
2025-09-26T02:48:02.079+09:00 INFO 96441 --- [fooddash-domain] [ virtual-246] [\] c.f.o.connector.SinkConnector : bulkHandle called with 100 records for table menus
SinkConnector.bulkHandle(..) execution time: 27.653 ms
2025-09-26T02:48:02.127+09:00 INFO 96441 --- [fooddash-domain] [MessageBroker-8] [\] c.f.o.connector.SinkConnector : bulkHandle called with 1 records for table menus
SinkConnector.bulkHandle(..) execution time: 1.658 ms
- In summary, because Redis Stream is memory-based, data loss can occur. To minimize loss, configure the
noevictionpolicy and MySQL -> Redis flow control. Since history and offsets are recorded and stored in Redis, CDC can resume from the Debezium Server restart point. Even if the offset that tracks how far the binlog was read is lost, starting the snapshot from the beginning is possible because Redis -> MongoDB is idempotent. If a sunk document may be modified, handle it according to the data operation policy, such as settingmodified=trueand skipping updates in the ETL module when it is true, or managing a separate read-only sink document.
Appendix
Checklist when adding a new table
- Create Row data class, using snake_case, nullable fields, BigDecimal/OffsetDateTime, etc.
- Create a domain document that extends
SinkClass. Implement sink connector and register it as aThis was changed to dynamically read streams that start with the@BeaninSinkBindingsConfig.sink_mysql.*prefix, making maintenance easier.- If denormalization is needed, refer to
OrderItem, using individual upsert andtoEntity. - Write Kotest + Testcontainers tests for c/u/d, multi-franchise, and edge cases.
- Review Debezium snapshot/signaling strategy. Does the existing row snapshot for this table need to be loaded or not?
- If needed, refer to the incremental snapshot strategy above.