실무에서 redis stream 으로 사용자에게 알림전송 시스템을 구축하면서 kafka 와 다른점들을 많이 느꼈다. 개인적으로 느낀 4개 주요 차이점 있는데 AI 의 힘을 빌리지 않고 정리해본다. 아래는 redis stream grafana 모니터링 화면이다(message i/o 처리량은 로깅하지 않았다).
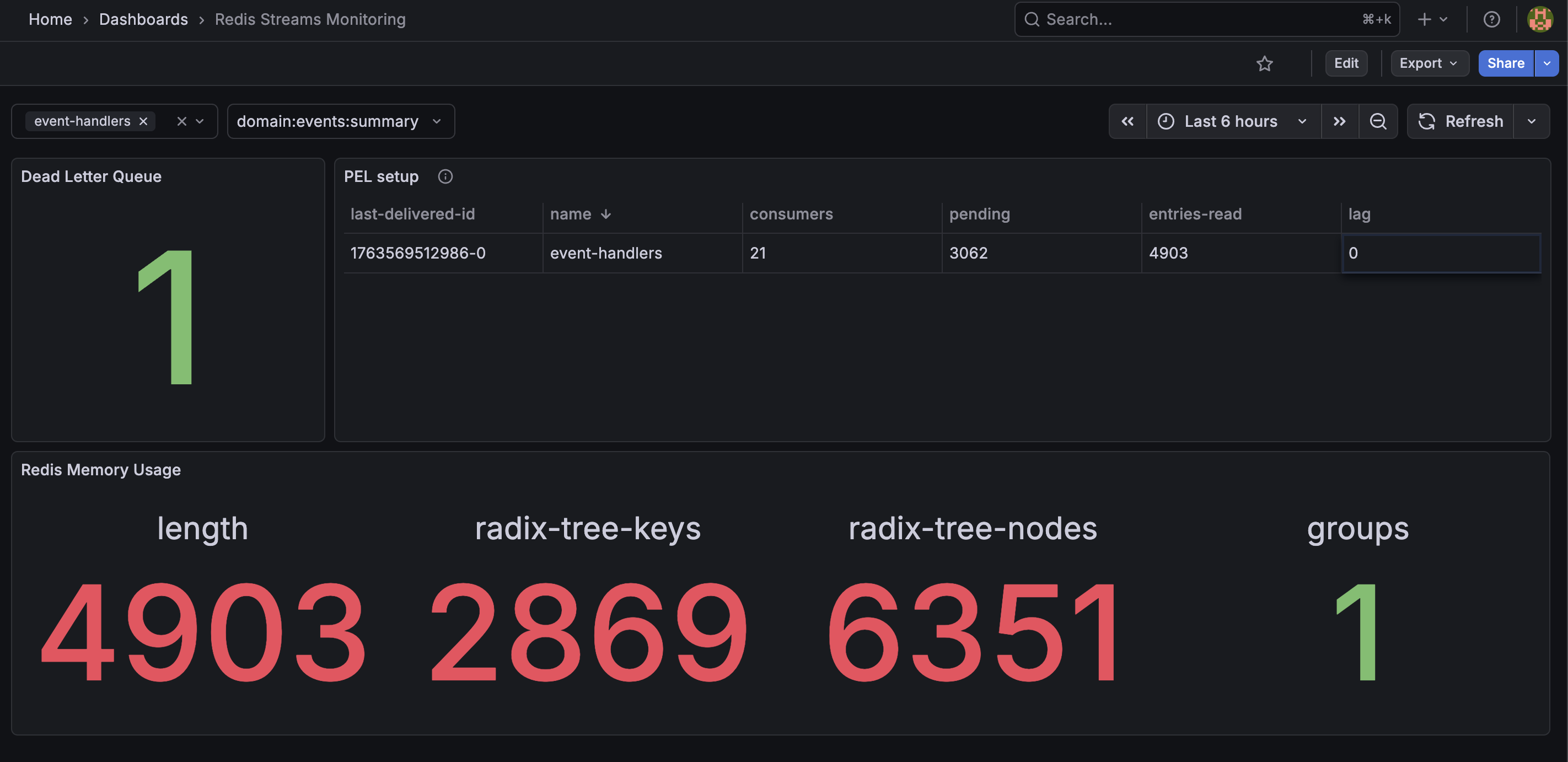
kafka 에서는 연결되어있는 consumer 자동관리해주는데 redis stream 은 그런거 없다. consumer 관리를 직접 등록해제 해줘야한다. 사실 consumer 싱크관리 안해줘서 지금 그림에서 보이듯 실제론 9개 conusmer 가 돌아가지만 21개 conusmer 가 등록되어있다. 그리고 리밸런싱도 직접 해줘야한다. kafka 처럼 리밸런싱 될 때 commit offset 이후부터 읽는게 아니라 얘네는 commit 자체가 없다. 아니, 정확히 말하면 kafka 에서의 commit 은 redis stream 에서는 두 단계로 나눠져 있다. 1. 하나는 소비자가 읽었음을 나타내는 단계. 2. 이후 xack 로 메세지를 소비자가 제대로 처리했음을 나타내는 단계.
stream 에서 새로운 컨슈머가 읽기만 하면(xack 안보내도) 그 시점부터는 새로운 컨슈머가 왔을 때 해당 메세지 이후부터만 읽는게 가능하다(xreadgroup). “Q. 그러면 만약에 읽다가 아예 컨슈머가 죽어버리면 어떻게 해요?” 라는 질문이 나올 수 있는데 kafka 의 경우에는 당연히 commit 안되어있고 리밸런싱 시간 지나면 알아서 새로운 컨슈머에 파티션 배정해주니까 괜찮다. redis stream 은 직접 리밸런싱 로직을 구현해줘야한다. 얘네는 컨슈머한테 전달 시 메세지를 PEL(pending entry list) 에 넣어둔다. 우리는 직접 컨슈머가 주기적으로 pel 내 들어있는 메세지들을 claim 해서 처리한 뒤 xack 전송해서 PEL 에서 제거시키도록 리밸런싱 로직을 “직접” 짜줘야한다. 이렇게 해놓으면 만약에 컨슈머가 읽는 도중에 죽어버리더라도 PEL 에 남아있는 메세지들을 다른 컨슈머가 가져가서 처리할 수 있다.
이거 멀티파드환경에서 리밸런싱 스케줄러 작성할 때 또 주의할 점이 있는데 더 말하면 너무 길어져서 이전 포스팅 링크를 남긴다.
- 또 다른점은 kafka 는 파티션 여러개 써서 동시성 가져갈 수 있는데, redis stream 애네는 파티션이 하나라는 점이다. 동시성을 하나만 가져갈 수 있게 되버리는데 이거 수정할려면 stream 을 여러개 만들고 해싱 + 모듈러 연산 조합으로 stream 여러개 나눠서 처러하도록 해야한다. 예로 뭐 user:stream:0, user:stream:1, user:stream:2 … user:stream:n 이런식으로 여러개 만들고, user id 를 해싱해서 stream 개수로 나눈 나머지 값에 따라 stream 을 골라서 넣고 빼도록 해야한다.
HASH(user_id) mod n = stream index이런식으로! 즉, 샤딩 해줘야함.물론 consumer 여러개를 단일 stream 에 붙일 수 있긴하다. 그런데 이러면 메세지 처리 순서문제가 발생한다. a 스레드가 먼저 메세지를 읽고 처리중일 때, b 스레드가 그 다음 메세지를 읽어서 더 빠르게 처리해버리면 순서가 꼬이게 된다. 그래서 단일 stream 에 여러 consumer 붙이는건 순서 보장이 필요한 상황에서는 적합하지 않다.
- kafka 는 debezium 이 커넥트 플러그인으로 DB 싱크도 지원해주는데, redis stream 은 그런거 없다. 보통 CQRS 해주기 위해서 읽기 전용 DB 싱크해주는 것을 이 MQ 를 백프레셔로 두고 여러 오픈소스 모듈에서 지원해주는데, kafka 는 커넥트 플러그인으로 DB 싱크도 지원해준다. redis stream 은 그런거 없다ㅜㅜ. debezium 에서 db -> redis stream 지원은 해주지만, redis stream -> sync readOnly db 지원이 없다ㅜㅜ. 그래서 직접 싱크 고성능 모듈을 따로 띄워야 한다. 그래서 직접 띄운다고 고생했다.ㅜ
- kafka 는 메세지 segment log 크기나 TTL 설정해서 자동 삭제해주는 옵션을 제공하는데 redis stream 은 XTRIM 으로 그냥 길이로만 제한한다. 직접 add 할 때 maxlen 옵션 줘서 길이 제한 걸어줘야 한다. 특히 메모리라서 꽉차버리면 키 제거해버려서 관리를 더 잘해줘야된다.
- kafka 는 exactly-once 기능 제공으로 A 메세지를 딱 한번 producing 보장해주는데, redis stream 은 그런거 없다. 그래서 동일 메세지를 여러번 쏠 수 있다. 이건 뭐 사실 구현이 간단해서 딱히 필요없다. 이벤트 uuid 레디스에 넣어놓고 produce 할 때 중복제거 해주면 된다. 사실 트랜젝션 코디네이터가 애초에 핸드쉐이킹때문에 느려서 우아한형제에서는 카프카 코디네이터 안쓰고 개별 구현으로 바꿨다고 한다. 물론 exactly-once 를 위한 이벤트 id 를 메모리에 저장한다고 했을 때, 사이즈가 꽤 커서 TTL 을 잘 설정해놔야한다.
acl 을 설정하는건 기본 kafka 랑 비슷하다. redis stream 도 acl 설정해줘야한다. 예를들어 stream:domain:events:* 이런식으로 패턴 매칭해서 xadd, xread, xgroup, xreadgroup 권한을 줘야한다. connection, info, scan, xrange 권한도 줘야한다.
ACL SETUSER user ~domain:events:summary* +xadd +xread +xgroup +xreadgroup ACL SETUSER user +@connection ACL SETUSER user +info ACL SETUSER user +scan +xrange
상당히 번거롭다고 볼 수 있다ㅜㅜ. kafka 가 사용하기엔 더 편하고 레퍼런스도 상당히 많아서 좋다. 물론 로우레벨에선 redis stream 으로 직접 조절할 수 있는게 많아서 더 재밌긴 하지만, 운영공수 측면에서는 kafka 가 좀 더 나아보인다.
While building a user notification system with Redis Stream in production, I felt many differences from Kafka. Personally, there were four major differences I noticed, so I am writing them down without leaning on AI. The image below is the Redis Stream Grafana monitoring screen. Message I/O throughput was not logged.
Kafka automatically manages connected consumers, but Redis Stream does not have that. You have to register and unregister consumers yourself. In fact, because I did not sync consumer management properly, the image currently shows that 21 consumers are registered even though only 9 consumers are actually running. You also have to implement rebalancing yourself. Unlike Kafka, where reading resumes from the committed offset after rebalancing, Redis Stream does not have commit in the same sense. More precisely, what Kafka calls commit is split into two stages in Redis Stream. 1. One stage indicates that the consumer has read the message. 2. The later
xackstage indicates that the consumer has processed the message properly.In a stream, once a new consumer reads a message, even if it does not send
xack, a new consumer can only read from after that message withxreadgroup. “Q. Then what if the consumer dies while reading?” This question naturally comes up. In Kafka, if the message was not committed and the rebalancing time passes, Kafka assigns the partition to a new consumer, so it is fine. With Redis Stream, you need to implement the rebalancing logic yourself. Redis Stream puts messages into the PEL, the pending entry list, when they are delivered to a consumer. We have to write the rebalancing logic ourselves so that a consumer periodically claims messages in the PEL, processes them, sendsxack, and removes them from the PEL. If this is set up, even if a consumer dies while reading, another consumer can take the messages left in the PEL and process them.There is another point to watch out for when writing a rebalancing scheduler in a multi-pod environment, but this would get too long, so I will leave a link to the previous post.
- Another difference is that Kafka can use multiple partitions to get concurrency, but Redis Stream has only one partition. This means you can only get one lane of concurrency. To fix this, you need to create multiple streams and process them by combining hashing and modulo operations. For example, create streams like
user:stream:0,user:stream:1,user:stream:2, …,user:stream:n, hash the user id, divide it by the number of streams, and pick the stream based on the remainder. Something likeHASH(user_id) mod n = stream index. In other words, you need sharding.Of course, you can attach multiple consumers to a single stream. But then message ordering becomes a problem. If thread A reads and starts processing a message first, and thread B reads the next message and finishes it faster, the order gets broken. So attaching multiple consumers to a single stream is not suitable when order must be guaranteed.
Kafka supports DB sync through Debezium as a Connect plugin, but Redis Stream does not have that. Usually, when building CQRS, several open source modules support syncing a read-only DB while using the MQ as backpressure. Kafka supports DB sync through Connect plugins. Redis Stream does not have that. Debezium supports DB -> Redis Stream, but there is no Redis Stream -> sync read-only DB support. So I had to run a separate high-performance sync module myself. That was painful.
Kafka provides options to delete messages automatically by configuring segment log size or TTL, but Redis Stream mostly limits by length with
XTRIM. You need to set a length limit directly with themaxlenoption when adding messages. Since it is memory-based, if memory gets full, keys can be evicted, so it needs stricter management.Kafka provides exactly-once features to guarantee that message A is produced exactly once, but Redis Stream does not have that. So the same message can be sent multiple times. In practice, this is not a big problem because the implementation is simple. Put an event UUID in Redis and remove duplicates when producing. In fact, because the transaction coordinator is slow due to handshaking, Woowa Brothers said they stopped using Kafka’s coordinator and changed to their own implementation. Of course, if you store event ids for exactly-once in memory, the size can get fairly large, so TTL needs to be configured carefully.
ACL configuration is similar to basic Kafka. Redis Stream also needs ACL configuration. For example, you need to pattern-match something like
stream:domain:events:*and grantxadd,xread,xgroup, andxreadgrouppermissions. You also needconnection,info,scan, andxrangepermissions.ACL SETUSER user ~domain:events:summary* +xadd +xread +xgroup +xreadgroup ACL SETUSER user +@connection ACL SETUSER user +info ACL SETUSER user +scan +xrange
Overall, it is quite cumbersome. Kafka is easier to use and has a lot more references, which is nice. Of course, Redis Stream is more fun at the low level because there are many things you can control directly, but in terms of operational effort, Kafka looks better.