서론
Sharding 관련 리밸런싱 알고리즘을 설계하다보니 자연스럽게 Kafka 리밸런싱 레퍼런스를 찾아보게되었다.
그리고 최근 KIP-848 에서 기존 consumer leader 가 어떤 파티션을 누가 맡을건지 리밸런싱 데이터를 group coordinator 에 전달했다면, 이제는 group coordinator 가 직접 assignment 를 계산해서 내려주도록 바뀌었다. 여기서 핵심은 단순히 assign 계산 위치가 바뀐게 아니라, 기존의 stop-the-world 기반 generation synchronization 을 제거하려는 방향이라는 점이다.
결국 본질은 파티션 ownership 관리 방식이 바뀐 것이다.
등장배경
기존 Kafka 는 “C1 consume P1 종료” -> “C3 consume P1 시작” 을 안전하게 처리하기 위해서 그냥 에라이 모르겠다. 일단 컨슈머 전체 멈추고 새 generation sync 맞춘 뒤 새 assignment 전체 전파하자 를 선택했다. 그런데 시간이 지나면서 왜 굳이 전체 중단해야해? 그냥 C1 - P1 consume stop -> C3 - P3 consume start 순서만 시퀀셜하게 관리해주면 전체중단 필요없잖아? 로 생각이 발전되었고 순서보장을 위해서 중앙제어가 필요한데 기존 코디네이터의 기능을 확장시켜 제어하도록 만들자! 로 결론이 난 게 이번 KIP-848 이다.
기존 kafka classic 리밸런싱 로직
- 코디네이터에서 컨슈머의 heartbeat 가 제때 안날라와서 리밸런싱 처리로 감지한다.
- 다른 consumer 들의 heartbeat 의 요청에 코디네이터는 “지금 generation 무효고 새로운 그룹싱크가 필요하니 JoinGroup 줘” 라고 응답한다.
- stop-the-world 발생하며 코디네이터가 리더 컨슈머를 선정하고 JoinGroup 으로 현재 컨슈머과 토픽들의 싱크된 메타데이터들을 전달한다.
- 리더 컨슈머가 어떤 파티션을 누가 구독할 지 정하고 코디네이터에게 전달하고 코디네이터는 이를 모든 컨슈머에게 전파한다.
일단 이게 기본 로직이다. 여기서 새로운 컨슈머 등장한다고 상황을 가정해본다면 위의 루프를 2번 반복할 수 있다.
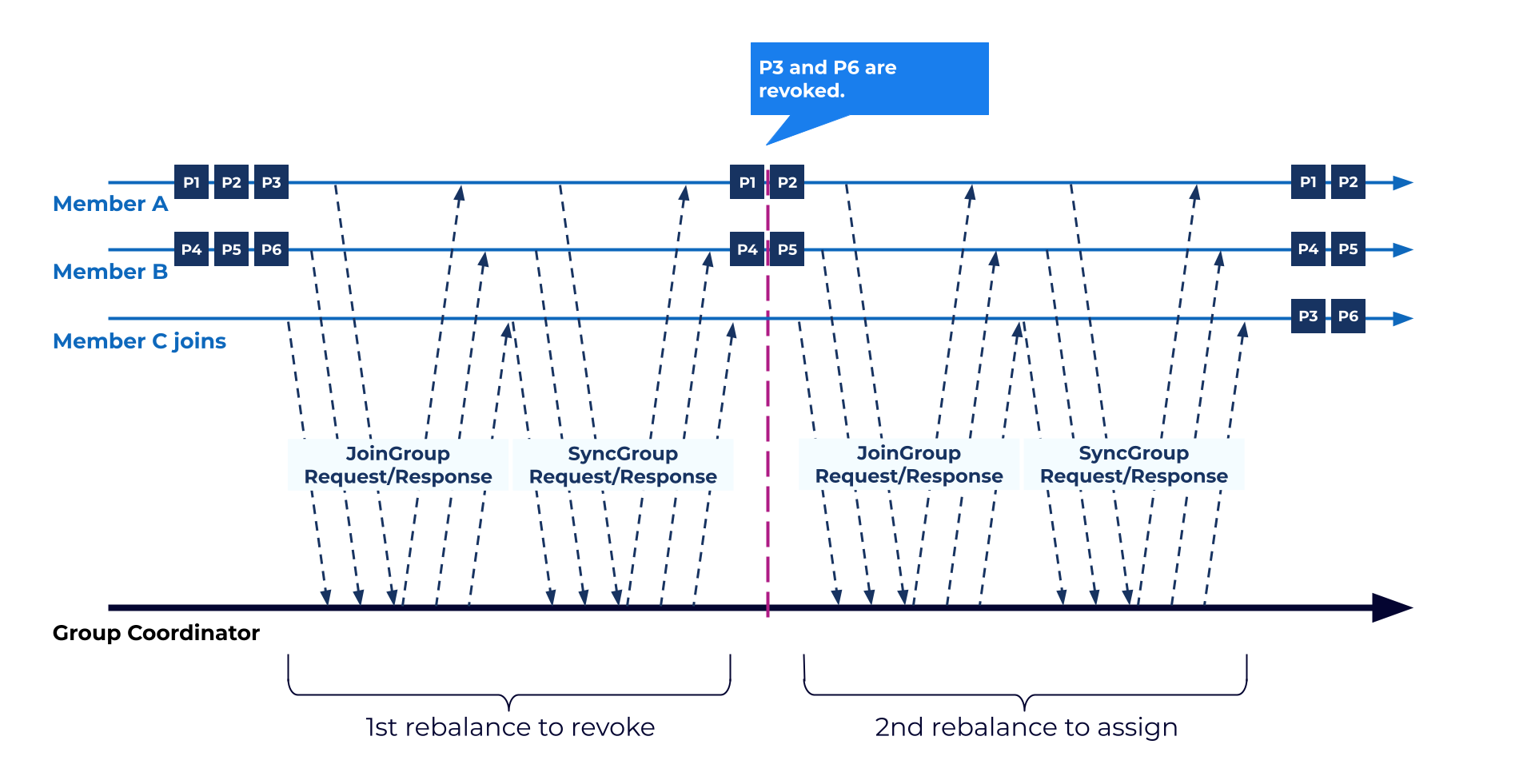
1) P3, P6 을 revoke 하는 루프 + 2) P3, P6 를 C3 에 할당하는 루프.
이렇게 굳이 2번 나눠서 하는 이유는 P3, P6 이 깔끔하게 반환되지않고 C3 에 바로 할당해버리면 중복소비가 될 수 있기 때문이다.
KIP-429 에선 CooperativeStickyAssignor 적용해서 이미 정상적으로 붙어있는 파티션은 그냥 놔둔다(그래도 여전히 stop-the-world 발생).
그래서 뭐가 바뀌는데?
라고 물어본다면 핵심은 서버기반 리밸런싱이 브로커기반 리밸런싱으로 바뀌었다.
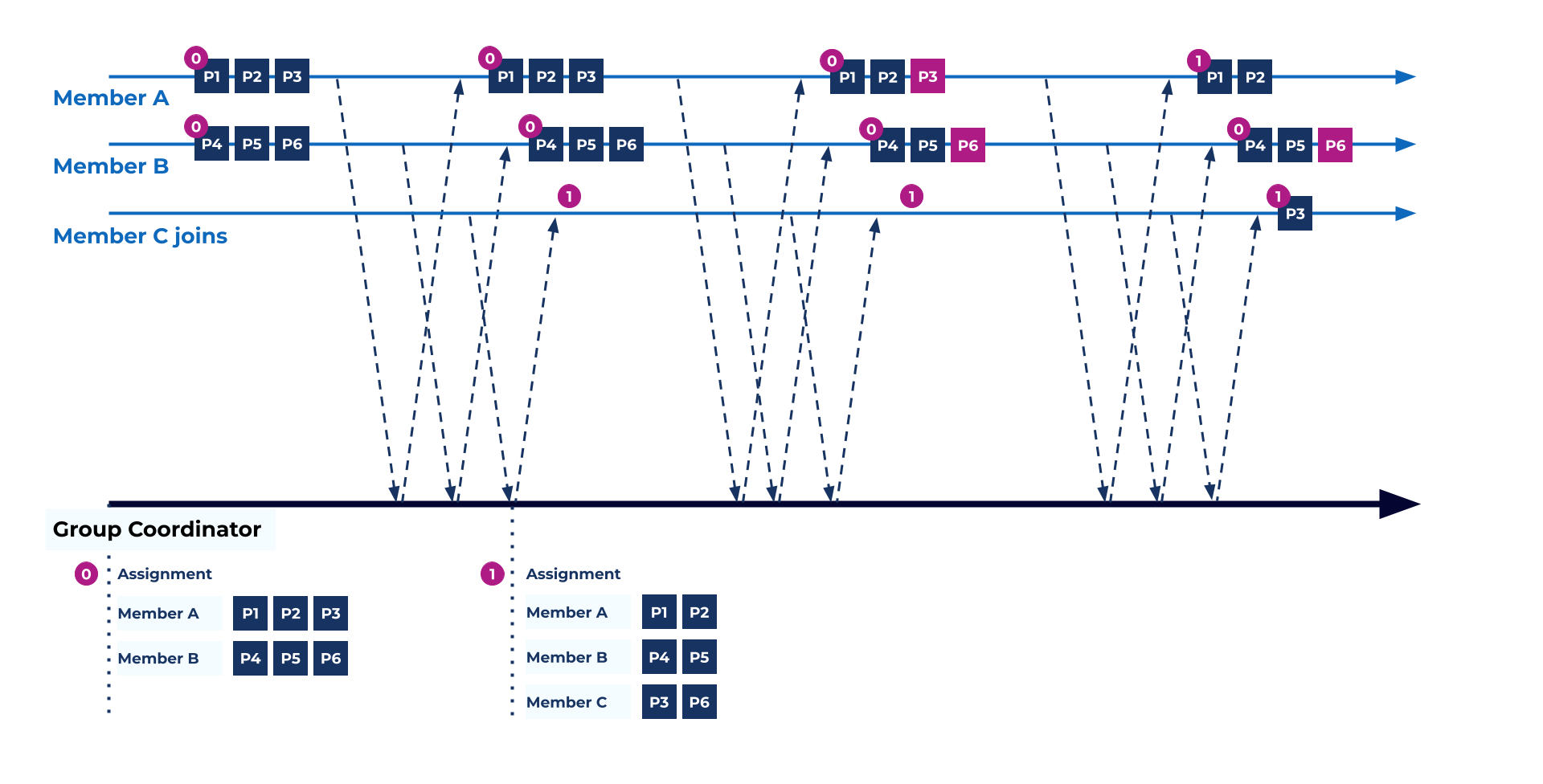
cooperative rebalance(KIP-429) 로 이동량은 줄였지만, 여전히 “그룹 전체가 잠깐 멈춰서 generation sync 를 맞춘다” 는 특성 자체는 남아있었다. 그러다가 아래의 그림처럼 바뀌었는데, 계속 P3, P6 기존 컨슈머 소비하다가 다음 heartbeat 에서 제대로 revoke 완료된 거 확인 후 코디네이터가 assign 해주면 잠깐 텀은 있겠지만 generation sync 를 위해 전체 중단을 굳이 하지 않아도 partially 하게 교체가능하다.
Why did Kafka KIP-848 appear?
While designing a rebalance algorithm for sharding, I naturally started looking at Kafka rebalance references.
In KIP-848, the assignment calculation changed. Previously, the consumer leader decided which consumer should own which partition and sent that rebalance data to the group coordinator. Now the group coordinator calculates the assignment directly and sends it down.
The important point is not just that the assignment calculation moved. The direction is to remove the old stop-the-world based generation synchronization.
In the end, the essence is that the way partition ownership is managed has changed.
Background
The old Kafka approach was roughly this:
To safely process “C1 stops consuming P1” -> “C3 starts consuming P1”, stop all consumers first, sync a new generation, and then propagate the new assignment.
Over time, the thinking evolved:
Why do we need to stop everyone? If we only sequence “C1 stops consuming P1” and “C3 starts consuming P1” correctly, full stop-the-world should not be necessary.
And the conclusion became:
Ordering needs centralized control, so let’s extend the coordinator’s responsibility and let it control the assignment.
That is the core idea behind KIP-848.
Existing Kafka classic rebalance flow
- The coordinator detects a rebalance condition because a consumer heartbeat does not arrive in time.
- In response to heartbeats from other consumers, the coordinator says, “The current generation is invalid. Send JoinGroup because a new group sync is needed.”
- Stop-the-world happens. The coordinator selects a leader consumer and sends synced metadata about current consumers and topics through JoinGroup.
- The leader consumer decides which consumer should subscribe to which partition, sends that to the coordinator, and the coordinator propagates it to every consumer.
This is the basic flow. If we assume a new consumer joins, the loop can happen twice.
1) A loop to revoke P3 and P6, and 2) another loop to assign P3 and P6 to C3.
The reason this is split into two steps is that assigning P3 and P6 directly to C3 before they are cleanly revoked can cause duplicate consumption.
KIP-429’s CooperativeStickyAssignor reduced unnecessary movement by keeping already stable partitions where they are. But stop-the-world still existed.
So what changed?
The core change is that server-based rebalance moved to broker-based rebalance.
Cooperative rebalance (KIP-429) reduced movement, but it still had the characteristic that the whole group briefly stopped to sync generation. With the new flow, as shown below, existing consumers can keep consuming P3 and P6. Then, after the coordinator confirms through a later heartbeat that revoke is complete, it can assign the partitions.
There may still be a short gap, but the important point is that replacement can happen partially without stopping the whole group just for generation sync.